06. Recurrent Neural Networks¶
![]()
Info
The following sources were consulted in preparing this material:
- Zhang, A., Lipton, Z. C., Li, M., & Smola, A. J. Dive into Deep Learning. Cambridge University Press. Chapter 9: Recurrent Neural Networks.
- Andrej Karpathy's lecture on makemore.
Up until this point, our neural network inputs had fixed size (e.g. an image had a fixed height and width). In sequences, however, order matters, and the number of steps may vary:
- a sentence is a sequence of words or characters
- a stock signal is a sequence of prices
- a video is a sequence of frames
- a patient history is a sequence of events
This simple change creates a big modeling problem. The number of steps is not known in advance and can vary widely, so the model cannot rely on a different set of parameters for each position in the sequence.
Imagine designing a model where step 1 uses parameters $W_1$, step 2 uses $W_2$, step 3 uses $W_3$, and so on. First, the architecture would only work for a fixed sequence length. If the model was built for sequences of length 20, it would simply have no parameters for step 21. Second, learning would become extremely inefficient. Each step-specific parameter would only be trained using data from that particular position in the sequence. The model would have to learn hundreds or thousands of separate rules instead of learning a single general rule that applies everywhere. Third, most sequential processes follow the same underlying dynamics over time. The rule for interpreting the next word in a sentence does not fundamentally change between the beginning and the end of the sentence. Similarly, the physical rules governing motion in video frames are the same at every time step. Because the process itself is repetitive, the model should learn one update rule that can be applied repeatedly.
Sequence modeling (unsupervised density modeling) has the goal of estimating the probability distribution of a sequence, $p(\mathbf{x}_1, \ldots, \mathbf{x}_T)$, without predicting a specific target. For the aformentioned reasons, sequence models use parameter sharing across time. The model learns a single function that updates a running summary of the past using the current input. This function is applied again and again as the sequence progresses, allowing the model to process sequences of any length while gradually accumulating information about what has happened so far.
Note
In sequences the order carries meaning. If we shuffle the words of a sentence, the meaning changes. If we shuffle the frames of a video, the event changes. Images are different: although they can technically be flattened into a sequence of pixels, their natural structure is spatial (a 2D grid).
import random
import torch
import matplotlib.pyplot as plt
%matplotlib inline
torch.manual_seed(42)
random.seed(42)
T = 1000
time = torch.arange(T, dtype=torch.float32)
start_price = 100
drift = 0.0003
volatility = 0.01
returns = drift + volatility * torch.randn(T)
price = start_price * torch.exp(torch.cumsum(returns, dim=0))
plt.figure(figsize=(10, 3))
plt.plot(time, price)
plt.title('Simulated financial index')
plt.xlabel('time step')
plt.ylabel('price')
plt.show()
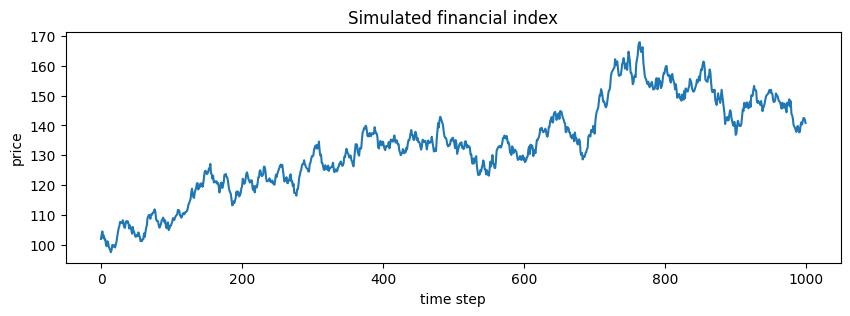
Autoregressive Modeling¶
One of the most common sequence tasks is to predict the next value from previous values. This is called autoregressive modeling. It appears in many domains, including time series forecasting, language modeling, audio generation, financial prediction, and several classes of generative models. Suppose we observe a sequence of values $x_1, x_2, \dots, x_{t-1}.$ If we want to predict the next value $x_t$, the only available signal may be the past observations themselves. Ideally, we would like to estimate the conditional distribution
$$ P(x_t \mid x_{t-1}, x_{t-2}, \dots, x_1). $$
In practice, modeling the entire distribution of a continuous variable can be difficult. A common simplification is to estimate a summary statistic, such as the conditional expectation:
$$ \mathbb{E}[x_t \mid x_{t-1}, x_{t-2}, \dots, x_1]. $$
There is an immediate problem, however. The amount of available history grows over time, meaning that the number of input features would continually increase. Standard models such as linear regression or neural networks expect fixed-length input vectors, so directly using the entire past is inconvenient. A simple trick (or rather, compromise) is to use fixed windows. Instead of conditioning on the entire past, we consider only the most recent $\tau$ observations:
$$ \hat{x}_t = f(x_{t-\tau}, \dots, x_{t-1}). $$
This keeps the number of inputs constant and converts the sequence prediction problem into a standard fixed-input learning problem.
def make_windows(x, tau):
X, y = [], []
for t in range(tau, len(x)):
X.append(x[t - tau:t])
y.append(x[t])
return torch.stack(X), torch.tensor(y).unsqueeze(1)
tau = 5
X, y = make_windows(price, tau)
f'Window matrix shape: {X.shape}, Target shape: {y.shape}'
'Window matrix shape: torch.Size([995, 5]), Target shape: torch.Size([995, 1])'
f'First window: {X[0]}, First target: {y[0]}'
'First window: tensor([101.9762, 103.5353, 104.5034, 102.3567, 103.0844]), First target: tensor([101.8502])'
f'Second window: {X[1]}, Second target: {y[0]}'
'Second window: tensor([103.5353, 104.5034, 102.3567, 103.0844, 101.8502]), Second target: tensor([101.8502])'
Instead of predicting directly from the entire history, we approximate the problem by using only the most recent $\tau$ observations. Each window becomes an input vector, and the value immediately following the window becomes the prediction target. For $\tau = 5$, the dataset looks like:
| input window | target |
|---|---|
| $(x_1, x_2, x_3, x_4, x_5)$ | $x_6$ |
| $(x_2, x_3, x_4, x_5, x_6)$ | $x_7$ |
| $(x_3, x_4, x_5, x_6, x_7)$ | $x_8$ |
| $\text{etc.}$ |
Once the dataset is constructed, we split it into a training and validation portion. Before training, it is also helpful to normalize the data. The following small utility class imitating sklearn.preprocessing.StandardScaler performs this standardization by subtracting the mean and dividing by the standard deviation computed from the training data.
class StandardScaler:
def fit(self, x):
self.mean = x.mean()
self.std = x.std()
def transform(self, x):
return (x - self.mean) / self.std
def inverse(self, x):
return x * self.std + self.mean
import torch.nn as nn
import torch.nn.functional as F
split = 700
X_train, y_train = X[:split], y[:split]
X_val, y_val = X[split:], y[split:]
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_val = scaler.transform(X_val)
y_train = scaler.transform(y_train)
y_val = scaler.transform(y_val)
model = nn.Sequential(
nn.Linear(tau, 32),
nn.Tanh(),
nn.Linear(32, 1)
)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2)
train_losses = []
val_losses = []
for epoch in range(400):
model.train()
pred = model(X_train)
loss = F.mse_loss(pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
val_pred = model(X_val)
val_loss = F.mse_loss(val_pred, y_val)
train_losses.append(loss.item())
val_losses.append(val_loss.item())
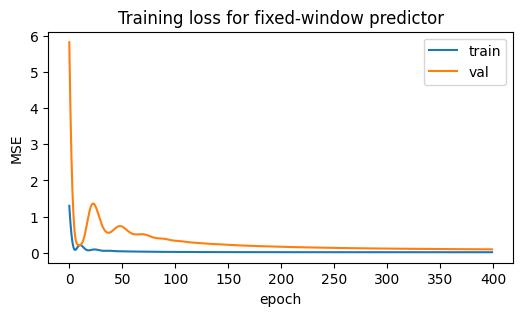
plt.figure(figsize=(6, 3))
plt.plot(train_losses, label='train')
plt.plot(val_losses, label='val')
plt.title('Training loss for fixed-window predictor')
plt.xlabel('epoch')
plt.ylabel('MSE')
plt.legend()
plt.show()
with torch.no_grad():
pred_val = model(X_val)
pred_val = scaler.inverse(pred_val)
y_val_true = scaler.inverse(y_val)
plt.figure(figsize=(10, 3))
plt.plot(range(split + tau, split + tau + len(y_val_true)), y_val_true.squeeze(), label='true')
plt.plot(range(split + tau, split + tau + len(pred_val)), pred_val.squeeze(), label='pred')
plt.title('Validation prediction vs true price')
plt.xlabel('time step')
plt.ylabel('price')
plt.legend()
plt.show()
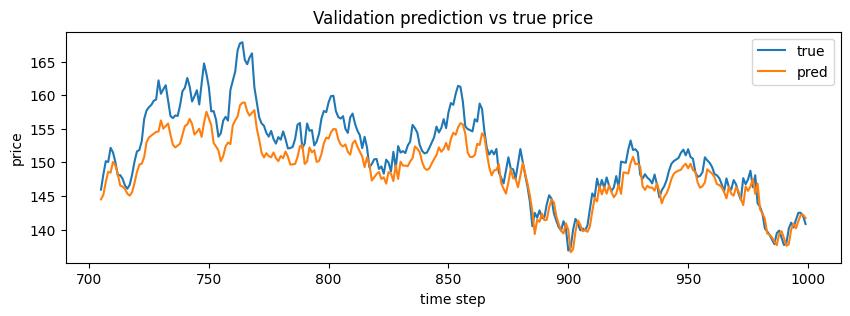
The plot above shows the model's one-step predictions compared to the true price sequence on the validation portion of the data. The network is able to capture the general movement of the signal, but its predictions appear noticeably smoother than the true sequence. This happens because the model is trained with mean squared error. When the next value is uncertain, the safest prediction is often a value close to the local average of the recent observations.
Another important limitation comes from the way we constructed the dataset. The model only receives the last $\tau$ values as input. Any information that occurred earlier than this window is completely ignored. In other words, the model has a fixed memory of length $\tau$. While the window approach allows us to use standard neural networks with fixed-size inputs, it is only an approximation to the original autoregressive problem or predicting the distribution.
Note
Using a fixed window can also be interpreted as making a Markov assumption. Instead of conditioning on the entire history, we assume that the next value depends only on the most recent $\tau$ observations: $$ P(x_t \mid x_1,\dots,x_{t-1}) \approx P(x_t \mid x_{t-\tau},\dots,x_{t-1}). $$
This is known as a $\boldsymbol{\tau}$-order Markov assumption. For the first-order Markov (the window size $\tau = 1$), it leads to: $$ P(x_t \mid x_1,\dots,x_{t-1}) \approx P(x_t \mid x_{t-1}). $$
In practice this assumption is rarely exactly true, but the influence of distant history often diminishes. Using a finite window therefore provides a practical approximation that can allow us to train models with fixed-size inputs.
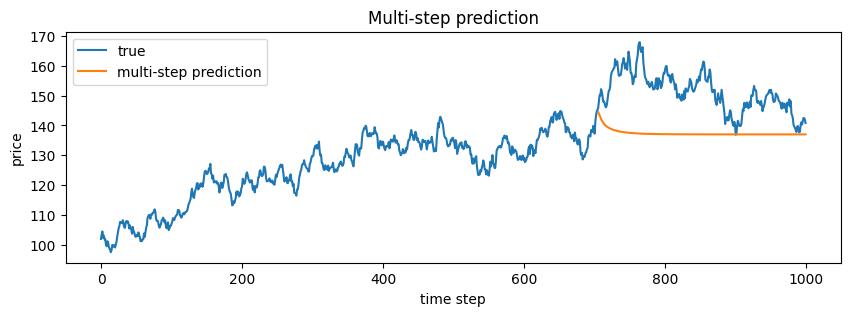
We now may attempt for a multi-step prediction. Unlike one-step prediction (as above), where the model always receives the true previous values, rollout forecasting feeds the model's own predictions back as future inputs. This makes the task much harder. Any small prediction error becomes part of the next input window, so errors can accumulate over time and the predicted trajectory may drift away from the true sequence. Later on, we will see how we can tackle this problem.
with torch.no_grad():
rollout = scaler.transform(price.clone())
for t in range(split + tau, T):
window = rollout[t - tau:t]
rollout[t] = model(window.unsqueeze(0)).squeeze()
rollout = scaler.inverse(rollout)
plt.figure(figsize=(10, 3))
plt.plot(time, price, label='true')
plt.plot(time[split + tau:], rollout[split + tau:], label='multi-step prediction')
plt.legend()
plt.title('Multi-step prediction')
plt.xlabel('time step')
plt.ylabel('price')
plt.show()
Language Modeling¶
Language modeling is the task of predicting the next word (or token) in a sequence based on the words that come before it. The model learns patterns in text so it can estimate how likely different sequences of words are. In most cases it is autoregressive, meaning the model generates text one token at a time using the previously generated tokens as context. A token is simply the atomic unit the model works with. Depending on the choice, a token can be a word, subword, character, etc. We will use character-level tokens for studying the sequence models in a simple and clear manner. A text sequence can be written as a list of tokens:
$x_1, x_2, x_3, \dots, x_T$,
where each $x_t$ is one token observed at time step $t$. The goal of a language model is to assign a probability to an entire sequence:
$P(x_1, x_2, \dots, x_T)$.
Once we know how to assign probabilities to sequences, we get several useful things automatically:
- we can compare which sentence is more plausible,
- we can generate text by sampling one token at a time,
- we can train models by rewarding high probability on the correct next token.
The chain rule of probability is helpful to turn language modeling into a next-token prediction problem:
Instead of trying to learn the whole sequence probability in one shot, we learn to repeatedly answer the question: given the tokens so far, what should come next? To experiment with language models we need a dataset of sequences.
import requests
import random
def load_names(source='makemore_aze', shuffle=True):
urls = {
'makemore': 'https://raw.githubusercontent.com/karpathy/makemore/master/names.txt',
'female': 'https://raw.githubusercontent.com/aznlp/names/master/female.txt',
'male': 'https://raw.githubusercontent.com/aznlp/names/master/male.txt',
}
if source == 'makemore':
words = requests.get(urls['makemore']).text.splitlines()
elif source == 'makemore_aze':
female = requests.get(urls['female']).text.splitlines()
male = requests.get(urls['male']).text.splitlines()
words = female + male
words = list(dict.fromkeys(words)) # remove duplicates, preserve order
elif source == 'female':
words = requests.get(urls['female']).text.splitlines()
elif source == 'male':
words = requests.get(urls['male']).text.splitlines()
else:
raise ValueError("source must be 'makemore', 'male', 'female', or 'makemore_aze'")
words = [w.strip().lower() for w in words if w.strip()]
if shuffle and source != 'makemore':
random.shuffle(words)
return words
words = load_names('makemore')
f'Number of names: {len(words)}. The first five words: {words[:5]}'
"Number of names: 32033. The first five words: ['emma', 'olivia', 'ava', 'isabella', 'sophia']"
Each element in words is a single name represented as a Python string. Since we will build a character-level language model, we need to work with the individual characters that appear in the dataset. The first step is to determine the vocabulary, i.e. the set of unique characters used across all names. We construct it by joining all names into one long string and taking the set of characters. Sorting the result makes the ordering deterministic, which is convenient for reproducibility. The vocabulary size is simply the total number of distinct tokens the model can produce.
Language models operate on numeric indices, not raw characters, so we create two lookup tables:
stoi(string → index): maps each character to a unique integer.itos(index → string): the inverse mapping that lets us convert indices back to characters.
We also introduce a special token . that marks the start and end of a sequence. This token allows the model to learn which characters tend to begin names and when a name should terminate.
chars = sorted(list(set(''.join(words))))
stoi = {ch: i + 1 for i, ch in enumerate(chars)}
stoi['.'] = 0
itos = {i: ch for ch, i in stoi.items()}
VOCAB_SIZE = len(stoi)
f'Vocabulary size: {VOCAB_SIZE}. STOI: {stoi}'
"Vocabulary size: 27. STOI: {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6, 'g': 7, 'h': 8, 'i': 9, 'j': 10, 'k': 11, 'l': 12, 'm': 13, 'n': 14, 'o': 15, 'p': 16, 'q': 17, 'r': 18, 's': 19, 't': 20, 'u': 21, 'v': 22, 'w': 23, 'x': 24, 'y': 25, 'z': 26, '.': 0}"
example = words[0]
encoded = [stoi[ch] for ch in example] + [stoi['.']]
f'Name: "{example}" Encoded: {encoded} Decoded: "{"".join(itos[i] for i in encoded)}"'
'Name: "emma" Encoded: [5, 13, 13, 1, 0] Decoded: "emma."'
Before building a model, it is useful to inspect some basic statistical properties of the dataset itself. It turns out the natural language is not distributed uniformly: a small number of tokens appear very often, while many others are rare. A famous empirical pattern describing such behavior is Zipf's law A scientific law typically refers to a precise, universally valid relationship that holds under well-defined conditions (for example, Newton's laws of motion or the laws of thermodynamics). Such laws are expected to be stable, reproducible, and grounded in a clear theoretical framework. In contrast, Zipf's law is empirical: it describes a pattern that is often observed in real data (especially language), but it is not exact, not universal, and does not arise from a single agreed-upon theory. A similar case is infamous Moore's law, which describes the growth of transistor counts in integrated circuits over time. If we rank tokens by frequency, then the frequency of the token with rank $i$ is often approximately
$$ n_i \propto \frac{1}{i^\alpha}, $$
where $n_i$ is the frequency and $\alpha$ is a positive constant. Even though our dataset is small and consists of names rather than full natural language text, we can still examine whether the character distribution has a similar long-tail shape. This helps build intuition for an important fact: language data is highly imbalanced, and rare events quickly become a problem for pure counting methods.
from collections import Counter
counts = Counter(''.join(words))
print("Top characters:")
for ch, f in counts.most_common(10):
print(f"{repr(ch):>4} : {f}")
Top characters: 'a' : 33885 'e' : 20423 'n' : 18327 'i' : 17701 'l' : 13958 'r' : 12700 'y' : 9776 's' : 8106 'o' : 7934 'h' : 7616
import numpy as np
freqs = np.array(sorted(counts.values(), reverse=True))
ranks = np.arange(1, len(freqs) + 1)
fig, ax = plt.subplots(1, 2, figsize=(10, 4))
ax[0].plot(ranks, freqs)
ax[0].set_title("Frequency vs Rank")
ax[0].set_xlabel("Rank")
ax[0].set_ylabel("Frequency")
ax[1].plot(ranks, freqs)
ax[1].set_xscale("log")
ax[1].set_yscale("log")
ax[1].set_title("Log-Log (Zipf)")
ax[1].set_xlabel("Rank")
ax[1].set_ylabel("Frequency")
plt.tight_layout()
plt.show()
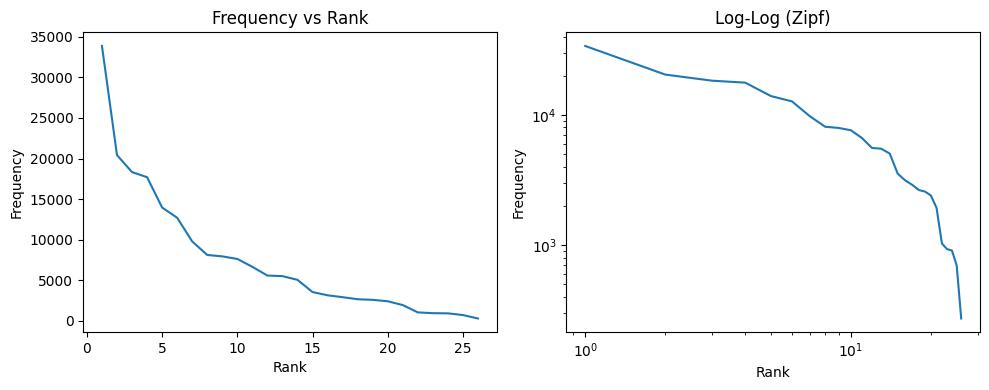
To make the structure of Zipf's law visible, we take logarithms:
$$ \log n_i = -\alpha \log i + c. $$
If Zipf’s law holds, the curve should appear approximately as a straight line with negative slope. As you can see, in our dataset, the log-log plot is not perfectly linear. This is expected, as the dataset is small (only names), we are working with characters, not words, and the rare characters introduce noise in the tail. Zipf's law becomes much clearer when we work on larger and more diverse datasets:
Before building a model, it is useful to inspect how characters follow one another in the dataset. The simplest possible language model is a bigram model, which assumes that the probability of the next character depends only on the previous character. Instead of using the full history, the bigram model approximates it with
$P(x_t \mid x_{t-1})$.
This is exactly first-order Markov assumption: the most recent token is treated as the only relevant context for predicting the next token. To estimate these probabilities from data, we count how often each character follows another. For every name we insert the boundary token . at the beginning and end:
. → a, a → n, n → n, n → a, a → ..
By collecting such transitions across the entire dataset, we can build a count matrix where each entry records how often one character is followed by another. This matrix will be the basis of our first language model.
N = torch.zeros((len(stoi), len(stoi)), dtype=torch.int32)
for w in words:
chs = ['.'] + list(w) + ['.']
for ch1, ch2 in zip(chs, chs[1:]):
i = stoi[ch1]
j = stoi[ch2]
N[i, j] += 1
N[:5, :5]
tensor([[ 0, 4410, 1306, 1542, 1690],
[6640, 556, 541, 470, 1042],
[ 114, 321, 38, 1, 65],
[ 97, 815, 0, 42, 1],
[ 516, 1303, 1, 3, 149]], dtype=torch.int32)
The matrix N stores how often one character is followed by another. Each row corresponds to the current character and each column corresponds to the next character. For example, the entry N[i, j] counts how many times character j appeared immediately after character i in the dataset. To make this easier to understand, we can visualize the matrix. To make the matrix interpretable, we can annotate it with the actual characters and the counts inside each cell. This allows us to directly read transitions such as how often a → n or n → a occurs in the dataset.
plt.figure(figsize=(10,10))
plt.imshow(N, cmap='Blues')
for i in range(VOCAB_SIZE):
for j in range(VOCAB_SIZE):
plt.text(j, i, itos[j], ha='center', va='bottom', fontsize=8, color='gray')
plt.text(j, i, int(N[i, j].item()), ha='center', va='top', fontsize=8)
plt.xticks(range(VOCAB_SIZE), [itos[i] for i in range(VOCAB_SIZE)], rotation=90)
plt.yticks(range(VOCAB_SIZE), [itos[i] for i in range(VOCAB_SIZE)])
plt.xlabel('Next Character')
plt.ylabel('Current Character')
plt.title('Bigram Counts with Character Labels')
plt.show()
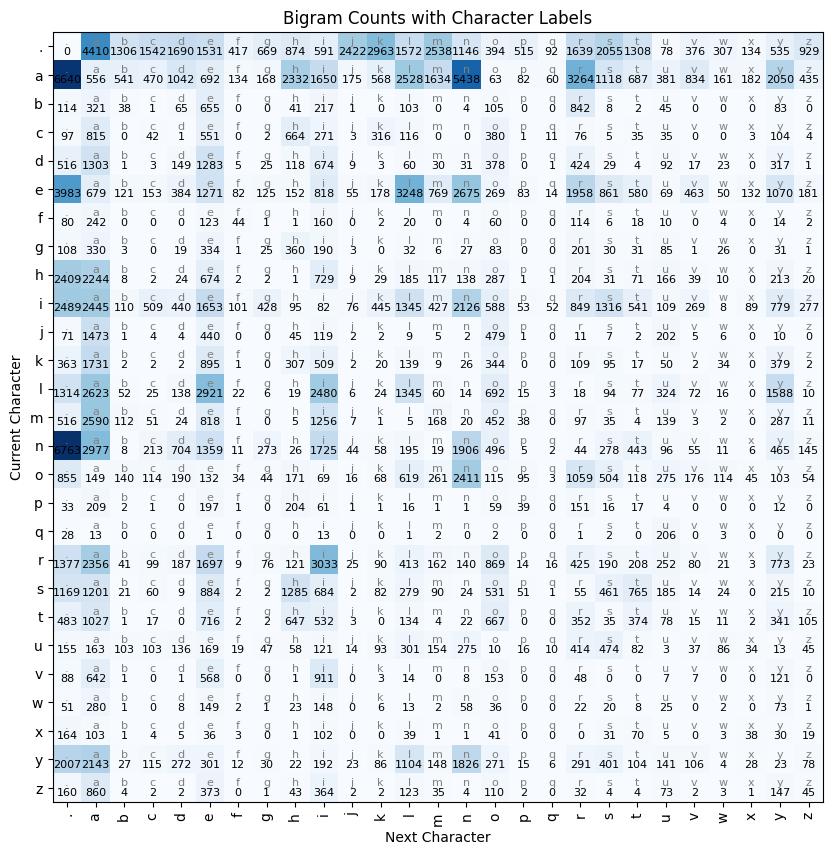
The count matrix tells us how often each transition occurs, but a language model needs probabilities, not raw counts. To convert counts into probabilities, we normalize each row of the matrix so that the values sum to 1. After normalization, every row represents a probability distribution over the possible next characters.
However, one issue remains: if a transition never appears in the dataset, its count will be zero. This assigns the transition probability zero. Since the probability of a sequence is computed as a product of such terms, a single zero makes the entire sequence probability zero. To avoid this, we apply additive (Laplace) smoothing, which adds a small constant $\alpha$ to every count:
$$ P_{ij} = \frac{N_{ij} + \alpha}{\sum_k (N_{ik} + \alpha)} $$
This ensures that no transition has zero probability. In this notebook, we use the simplest case $\alpha = 1$. This is not always optimal in practice, but it is sufficient here to avoid zero probabilities and keep the model well-defined.
P = (N + 1).float()
P = P / P.sum(dim=1, keepdim=True)
row = stoi['a']
for j in torch.topk(P[row], 5).indices.tolist():
print(f"P(next='{itos[j]}' | current='a') = {P[row, j]:.4f}")
P(next='.' | current='a') = 0.1958 P(next='n' | current='a') = 0.1604 P(next='r' | current='a') = 0.0963 P(next='l' | current='a') = 0.0746 P(next='h' | current='a') = 0.0688
To generate text from the model, we do not always pick the most probable next character. Instead, we sample from the probability distribution. This means more likely characters are chosen more often, but less likely ones can still appear occasionally. PyTorch provides torch.multinomial for this purpose. Given a probability vector, it returns an index sampled according to those probabilities. This is why the same model can generate different names each time we run it.
p = torch.tensor([0.7, 0.2, 0.1])
samples = torch.multinomial(p, num_samples=10, replacement=True)
f'Probabilities: {p.tolist()}'
'Probabilities: [0.699999988079071, 0.20000000298023224, 0.10000000149011612]'
f'Sampled indices: {samples.tolist()}'
'Sampled indices: [1, 2, 0, 0, 0, 0, 0, 0, 0, 0]'
Once we have the probability matrix P, we can generate new names by sampling characters one at a time. We begin with the start token .. The row corresponding to the current character gives a probability distribution over the possible next characters, and we randomly sample from that distribution. The sampled character becomes the new current character, and the process repeats. Generation stops when the model produces the boundary token . again. This means the model decided the sequence should end. Because the sampling is probabilistic, the model can generate many different names, even though it was trained on a fixed dataset.
num_samples = 10
g = torch.Generator().manual_seed(42)
names = []
for _ in range(num_samples):
out = []
ix = 0
while True:
ix = torch.multinomial(P[ix], num_samples=1, replacement=True, generator=g).item()
out.append(itos[ix])
if ix == 0:
break
names.append(''.join(out))
names
['anugeenvi.', 's.', 'mabidushan.', 'stan.', 'silaylelaremah.', 'li.', 'le.', 'epiachalen.', 'diza.', 'k.']
So far the model has learned how to generate names by sampling from the learned transition probabilities. But a language model should also be able to evaluate sequences. In other words, given a sequence of characters, how likely does the model think that sequence is? Under the bigram model, the probability of a sequence is computed by multiplying the conditional probabilities of each transition. For a name like anna, the sequence becomes . a n n a ., and its probability is
$P(a \mid .)\,P(n \mid a)\,P(n \mid n)\,P(a \mid n)\,P(. \mid a)$.
Because probabilities are small numbers, multiplying many of them quickly produces extremely tiny values. To make computation stable and easier to interpret, we work in log-space, adding log-probabilities instead of multiplying probabilities.
p = torch.linspace(0.001, 1.0, 200)
log_p = torch.log(p)
def plot_logp(p1, p2, p3):
fig, ax = plt.subplots(1, 3, figsize=(12,4))
for a, pv in zip(ax, [p1, p2, p3]):
y = torch.log(torch.tensor(pv)).item()
a.plot(p, log_p)
a.scatter([pv], [y], color='red')
a.set_title(f'p={pv:.2f} | logp={y:.2f}')
plt.tight_layout(); plt.show()
plot_logp(0.95, 0.2, 0.02)
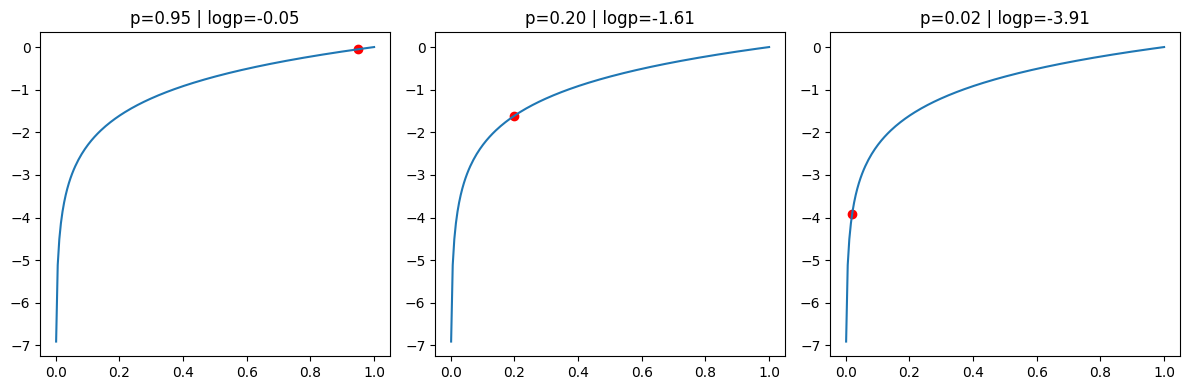
The plot shows how probabilities are transformed by the logarithm. Values close to 1 map to values near 0, while small probabilities map to large negative values. This makes the scale more informative: confident predictions (high probability) stay near 0, while unlikely predictions are pushed far down. In practice, probabilities can sometimes be exactly 0, and $\log(0)$ is undefined (it goes to $-\infty$). This is another reason we avoid zero probabilities (e.g. with smoothing) and prefer working in log-space, which is more stable when combining many probabilities.
example = words[0]
chs = ['.'] + list(example) + ['.']
logp = 0.0
transitions = []
for ch1, ch2 in zip(chs, chs[1:]):
i = stoi[ch1]
j = stoi[ch2]
p = P[i, j].item()
logp += torch.log(P[i, j]).item()
transitions.append((f'{ch1} -> {ch2}', p))
f'Log-probability: {logp}.'
'Log-probability: -12.571641862392426.'
The function above computes the log-probability of a name under the bigram model. For each pair of consecutive characters, it looks up the corresponding probability in the matrix P. Instead of multiplying all transition probabilities directly, it adds their logarithms. This is mathematically equivalent, but much more stable numerically. The transitions list is included only for inspection: it shows each character-to-character step together with its probability. The final logp value summarizes how plausible the whole name is according to the model. Higher log-probability means the sequence is considered more likely.
To evaluate the model more systematically, we compute the average negative log-likelihood (NLL) over the dataset. For every transition in every name, we take the negative logarithm of the probability assigned by the model and average these values. Lower NLL means the model assigns higher probability to the observed data, which indicates a better fit.
Important
The average NLL is exactly the cross-entropy between the empirical data distribution and the model distribution.
In other words, it measures how many "nats" (or bits, if using base-2 logarithms) are required on average to encode the data when using the model's probabilities. If the model perfectly matched the true data distribution, this value would reduce to the Shannon entropy, which represents the inherent uncertainty of the data itself. In practice, NLL is higher than entropy because the model is only an approximation.
Note
We compute NLL as an average over the dataset:
$$ \frac{1}{N} \sum_{i=1}^N -\log Q(x_i), $$
while cross-entropy is defined theoretically as
$$ -\sum_x P(x)\log Q(x). $$
These are the same quantity: the dataset average is an empirical estimate of the expectation under the true (unknown) data distribution $P$.
Tip
We have alredy discussed negative log-likelihood and related concepts in probabilistic modeling.
A commonly reported metric derived from NLL is perplexity, defined as
$$ \text{Perplexity} = e^{\text{NLL}} = e^{H(P, Q)}, $$
where $H(P, Q)$ denotes the cross-entropy between the data distribution $P$ and the model distribution $Q$. Perplexity can be understood as the effective number of equally likely choices the model is uncertain between when predicting the next token. For example, a perplexity of 5 suggests that the model behaves as if it were choosing among roughly five equally probable characters at each step.
This interpretation comes from the following observation. If the model assigned equal probability to $k$ possible tokens, then the probability of the correct token would be $1/k$. The negative log-likelihood would be $\log k$, and exponentiating it gives $k$, which matches the perplexity. In practice, model probabilities are not uniform, so this should be seen as an intuitive approximation. Lower perplexity therefore indicates a stronger language model, as it reflects higher probability assigned to the correct next tokens and reduced uncertainty in predictions.
Note
Perplexity became standard in language modeling because it converts log-based quantities (e.g. cross-entropy), which are difficult to interpret directly, into a more intuitive scale. Instead of abstract logarithmic values, it returns an effective number of choices, making it easier for humans to compare models and reason about uncertainty.
total = 0.0
count = 0
for w in words:
chs = ['.'] + list(w) + ['.']
for ch1, ch2 in zip(chs, chs[1:]):
i = stoi[ch1]
j = stoi[ch2]
total += -torch.log(P[i, j]).item()
count += 1
nll = total / count
perplexity = torch.exp(torch.tensor(nll)).item()
f'Average negative log-likelihood: {nll:.4f} / Perplexity: {perplexity:.4f}'
'Average negative log-likelihood: 2.4546 / Perplexity: 11.6415'
The bigram model is useful because it is simple, interpretable, and easy to build directly from counts. It can already capture basic local structure such as which characters tend to start names and which characters commonly follow others. However, it has a major limitation: every prediction depends only on the immediately previous character. This means the model treats all contexts ending in the same character as identical. For example, if the current character is a, the model always uses the same next-character distribution, regardless of whether the preceding sequence was ma, la, or anna. In other words, it has no memory beyond one step.
To model richer patterns, we need a method that can use more context. One possibility is to extend the idea from bigrams to trigrams or, more generally, to n-gram models, where the next token depends on the previous $n-1$ tokens. This gives the model more information, but it also increases the number of possible contexts dramatically. Many contexts become rare or never appear at all, which makes pure counting methods increasingly inefficient. So the next step is to keep the same next-token prediction framework, but allow the model to condition on a longer context in a more flexible way.
The vanilla bigram model also has a limitation of entirley being based on counting. The model cannot improve beyond the data it has seen, and it does not generalize to unseen or rare patterns. Instead, we can move to a different idea where we learn the probabilities. Rather than storing counts, we will assign a set of learnable parameters that produce scores for each possible next character. These scores are called logits. Given a current character $i$, the model will output a vector, where each value represents how strongly the model prefers a particular next character. These logits will be converted to probabilities via the softmax function.
Neural N-gram Language Models¶
One way to extend the bigram idea is to increase the amount of context used for prediction. Instead of conditioning only on the previous character, we can condition on the previous multiple characters:
$P(x_t \mid x_{t-n+1}, \dots, x_{t-1})$.
This is exactly k-th order Markov assumption. Using more context can improve predictions, but we mentioned that pure count-based methods quickly become impractical. The number of possible contexts grows exponentially with the context length, and many combinations appear rarely or never in the dataset. Therefore, a more flexible approach is to let a neural network learn how to use the context. Instead of storing large count tables, we convert the previous characters into vectors and train a small neural network to predict the next character.
The overall idea remains exactly the same as before: given a context of previous tokens, the model outputs a probability distribution over the next token. The difference is that the probabilities are produced by a learned neural network rather than by counting transitions in a table.
To train a neural n-gram model, we must convert the dataset into input–target pairs. Each training example consists of a fixed-length context and the character that follows it. Suppose the context length is 3. For the name anna, with boundary tokens added, the training pairs become:
| Context | Target |
|---|---|
. . . |
a |
. . a |
n |
. a n |
n |
a n n |
a |
n n a |
. |
Here the context always contains the previous three characters, and the model learns to predict the next character that follows that context. These will become the inputs and targets for training the neural network.
def build_dataset(words, block_size=3):
X, Y = [], []
for w in words:
context = [0] * block_size
for ch in list(w) + ['.']:
ix = stoi[ch]
X.append(context)
Y.append(ix)
context = context[1:] + [ix]
return torch.tensor(X), torch.tensor(Y)
BLOCK_SIZE = 3
X, Y = build_dataset(words, BLOCK_SIZE)
f'X shape: {tuple(X.shape)} | Y shape: {tuple(Y.shape)}'
'X shape: (228146, 3) | Y shape: (228146,)'
Each row in X represents a context of previous characters, encoded as integer token ids, while the corresponding entry in Y is the target character the model should predict. For example, if a row in X is [0, 0, 1], it represents the context ., ., a. The corresponding value in Y might be 13, which maps to some character such as n. During training, the model receives the context [0, 0, 1] and learns to assign high probability to the correct next character. Inspecting a few examples helps verify that the dataset was constructed correctly.
[( [itos[i] for i in X[k].tolist()], itos[Y[k].item()] ) for k in range(10)]
[(['.', '.', '.'], 'e'), (['.', '.', 'e'], 'm'), (['.', 'e', 'm'], 'm'), (['e', 'm', 'm'], 'a'), (['m', 'm', 'a'], '.'), (['.', '.', '.'], 'o'), (['.', '.', 'o'], 'l'), (['.', 'o', 'l'], 'i'), (['o', 'l', 'i'], 'v'), (['l', 'i', 'v'], 'i')]
Embeddings¶
Neural networks require continuous vector inputs, so we cannot use raw token indices directly. Instead, we map each token to a learned dense vector representation called an embedding.
The well-known one-hot encoding represents each token as a vector of length equal to the vocabulary size, with a single 1 at the token’s position and 0s elsewhere. For small vocabularies, this is manageable. However, as the vocabulary grows (e.g. 10,000 words), one-hot vectors become extremely large and inefficient: they waste memory, require unnecessary computation, and contain no notion of similarity. Any two one-hot vectors are orthogonal, so their dot product is always 0.
Note
One might ask: why not just use integer indices directly (e.g. $'b' \rightarrow 2$)? This is also problematic, because indices introduce a false sense of order and distance (recall the ordinal/categorical variables from a course on statistics). The model may interpret token 3 as being "closer" to token 2 than to token 10, even though tokens are purely categorical and have no inherent ordering. This creates an incorrect inductive bias.
import torch.nn.functional as F
chs = ['.'] * BLOCK_SIZE + list(words[0]) # "...emma"
ix = torch.tensor([stoi[c] for c in chs])
x_onehot = F.one_hot(ix, num_classes=VOCAB_SIZE).float()
plt.imshow(x_onehot)
<matplotlib.image.AxesImage at 0x7bc384903ad0>

We therefore need a representation that is both compact and meaningful. Embeddings provide exactly this: each token is mapped to a dense vector that can be learned from data. Embeddings are equivalent to one-hot encoding followed by a matrix multiplication. If a token is represented by a one-hot vector $x$ and multiplied by a weight matrix $C$, the result simply selects one row of that matrix:
$$ x C = C[i] $$
where $i$ is the index of the active entry. In practice, we skip constructing the one-hot vector and directly retrieve the corresponding row using C[X]. This is mathematically identical, but far more efficient. An embedding matrix $C \in \mathbb{R}^{V \times d}$ maps each token index to a dense vector of dimension $d$, where $V$ is the vocabulary size. These embeddings are parameters of the model: they are initialized randomly and updated during training to reflect how tokens are used in context.
For example, consider the contexts:
- $['b', 'a', 'd', 'a'] \rightarrow 'm'$
- $['m', 'a', 'd', 'a'] \rightarrow 'm'$
To correctly predict the same target in both cases, the model is encouraged to learn similar representations for $'b'$ and $'m'$. More generally, tokens that appear in similar contexts will have embeddings that move closer together during training.
The embedding dimension $d$ controls how much information each token representation can carry. Here we use $d = 2$, which is sufficient for a small dataset and allows easy visualization. However, this is a simplification: if $d$ is too small, the model cannot represent enough structure, if it is too large, it may overfit and require more data and computation. In larger language models, embedding dimensions are typically much higher to capture more detailed relationships.
EMBED_DIM = 2
C = torch.randn((VOCAB_SIZE, EMBED_DIM))
C[X].shape
torch.Size([228146, 3, 2])
Each context now consists of several embedding vectors — one for each character in the context. Unlike one-hot encodings, embeddings are learned and allow the model to represent similarities between characters, so similar contexts can share statistical strength. Before passing them to a neural network, we typically flatten these vectors into a single feature vector so the network can process the entire context together. The flattened embedding vectors will represent the input features for the neural network. The next step is to map these features to scores for each possible next character. We do this with a simple linear layer.
emb = C[X]
emb_flat = emb.view(emb.shape[0], -1)
W1 = torch.randn((BLOCK_SIZE * EMBED_DIM, VOCAB_SIZE))
b1 = torch.randn(VOCAB_SIZE)
logits = emb_flat @ W1 + b1
logits.shape
torch.Size([228146, 27])
We already know that the values in logits are scores produced by the neural network for each possible next character. Larger values indicate that the model considers that character more likely, but these scores are not yet probabilities. To convert logits into probabilities, we apply the softmax function. As softmax function relies on exponentiation, let's discuss it briefly.
The exponential function has two important properties that make it suitable for converting logits into probabilities: it is always positive, $e^x > 0$ for all $x$, and small increases in $x$ lead to large increases in $e^x$:
- $e^1 \approx 2.7$
- $e^2 \approx 7.4$
- $e^3 \approx 20$.
This means that slightly larger logits become disproportionately larger after exponentiation, allowing the model to express strong preferences between tokens. Similar to the logirthm function, exponentiation preserves ordering.
def softmax(logits):
logits = logits - logits.max(dim=1, keepdim=True).values # to avoid numerical overflow
exp_logits = torch.exp(logits)
return exp_logits / exp_logits.sum(dim=1, keepdim=True)
probs = softmax(logits)
probs.shape, probs[0].sum()
(torch.Size([228146, 27]), tensor(1.0000))
For each training example, the model produces a probability distribution over the vocabulary. The correct next character for that example is stored in Y. To measure how well the model predicts the correct characters, we compute the NLL of those probabilities to define our loss.
loss = -torch.log(probs[torch.arange(X.shape[0]), Y]).mean()
f'Initial loss: {loss.item():.4f}'
'Initial loss: 7.2687'
The loss above measures how well the model predicts the correct next characters. This loss is exactly the cross-entropy loss used in classification. In practice, it is often implemented in a more numerically stable way by combining the softmax and logarithm into a single function. To improve the predictions, we will apply gradient descent.
Info
The idea of learning word representations jointly with a neural language model was popularized by Bengio et al. (2003). This work introduced the use of embeddings and feedforward neural networks for language modeling, laying the foundation for many modern approaches.
BLOCK_SIZE = 3
X, Y = build_dataset(words, BLOCK_SIZE)
HIDDEN_SIZE = 100 # layer size
# trainable parameters
C = torch.randn((VOCAB_SIZE, EMBED_DIM), requires_grad=True)
W1 = torch.randn((BLOCK_SIZE * EMBED_DIM, HIDDEN_SIZE), requires_grad=True)
b1 = torch.randn(HIDDEN_SIZE, requires_grad=True)
W2 = torch.randn((HIDDEN_SIZE, VOCAB_SIZE), requires_grad=True)
b2 = torch.randn(VOCAB_SIZE, requires_grad=True)
params = [C, W1, b1, W2, b2]
def forward_pass(X, params):
C, W1, b1, W2, b2 = params
emb = C[X]
emb_flat = emb.view(X.shape[0], -1)
h = torch.tanh(emb_flat @ W1 + b1)
logits = h @ W2 + b2
return logits
def train_step(X, Y, params, optimizer):
logits = forward_pass(X, params)
loss = F.cross_entropy(logits, Y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss
def eval_loss(X, Y, params):
with torch.no_grad():
logits = forward_pass(X, params)
loss = F.cross_entropy(logits, Y)
return loss
def print_progress(e, epochs, loss, print_every=10):
if (e + 1) % print_every == 0:
print(f'[{e+1}/{epochs}] | Loss: {loss.item():.4f}')
epochs = 100
lr = 0.001
optimizer = torch.optim.Adam(params, lr=lr)
for e in range(epochs):
loss = train_step(X, Y, params, optimizer)
print_progress(e, epochs, loss)
[10/100] | Loss: 16.3297 [20/100] | Loss: 15.1789 [30/100] | Loss: 14.0995 [40/100] | Loss: 13.1102 [50/100] | Loss: 12.2120 [60/100] | Loss: 11.3929 [70/100] | Loss: 10.6486 [80/100] | Loss: 9.9676 [90/100] | Loss: 9.3403 [100/100] | Loss: 8.7742
Mini-batch training¶
So far, we have used the entire dataset in every training step. It is simple and useful for understanding the mechanics of forward pass, loss computation, backpropagation, and parameter updates. However, it becomes inefficient as the dataset grows. Instead of computing the loss over all training examples at once, we can randomly sample a small subset called a mini-batch and use only that subset for one gradient update.
Tip
We have already menioned mini-batches when discussing stochastic gradient descent.
If the full dataset contains $N$ examples and the mini-batch contains only $B \ll N$ examples, then each training step requires much less computation. This makes each update faster and reduces memory usage. In practice, this is one of the main reasons neural networks can be trained efficiently on large datasets.
Recall that mini-batch training also introduces a small amount of randomness into the gradient. Since each batch is only an approximation of the full dataset, the gradient is noisy rather than exact. This may seem undesirable at first, but in practice it is often helpful: the noise can prevent the optimization from getting stuck in poor local minima and usually leads to faster overall training.
def sample_batch(X, Y, batch_size=32):
ix = torch.randint(0, X.shape[0], (batch_size,))
return X[ix], Y[ix]
In the code below, we randomly sample batch_size training examples at each step. The rest of the forward and backward computation remains exactly the same, only the subset of data changes. Notice how the training is extremely quick this time, while decreasing the loss. We can even train it for longer.
epochs = 1000
print_every = epochs // 10
lr = 0.001
optimizer = torch.optim.Adam(params, lr=lr)
BATCH_SIZE = 64
for e in range(epochs):
Xb, Yb = sample_batch(X, Y, BATCH_SIZE)
train_step(Xb, Yb, params, optimizer)
if (e + 1) % print_every == 0:
loss = eval_loss(X, Y, params)
print_progress(e, epochs, loss, 1)
[100/1000] | Loss: 6.2244 [200/1000] | Loss: 4.9301 [300/1000] | Loss: 4.2621 [400/1000] | Loss: 3.9017 [500/1000] | Loss: 3.6606 [600/1000] | Loss: 3.4714 [700/1000] | Loss: 3.3338 [800/1000] | Loss: 3.2170 [900/1000] | Loss: 3.1293 [1000/1000] | Loss: 3.0568
Even though this model is still simple, it is already more flexible than the bigram count table. The prediction now depends on a fixed-length context of multiple previous characters, and the model can learn shared patterns across similar contexts through its parameters rather than memorizing every transition separately. Once training is complete, we can use the learned probabilities to generate new names by repeatedly feeding the model the current context, predicting the distribution over the next character, sampling one character, updating the context, and continuing until the boundary token . is produced.
names = []
with torch.no_grad():
for _ in range(num_samples):
context = [0] * BLOCK_SIZE
out = []
while True:
x_context = torch.tensor([context])
logits = forward_pass(x_context, params)
probs = F.softmax(logits, dim=1)
ix = torch.multinomial(probs[0], num_samples=1, generator=g).item()
if ix == 0:
break
out.append(itos[ix])
context = context[1:] + [ix]
names.append(''.join(out))
names
['gom', 'joeeradra', 'la', 'mikhlyna', 'acvihinea', 'zalsnieiar', 'tpcjlamaa', 'tay', 'senayl', 'dokn']
To get familiar with the PyTorch formulation (which we will use in the future sections), we will rewrite our model using nn.Module. Note how embedding is initialized and used. The model is equivalent to what we had just seen above.
class NGram(nn.Module):
def __init__(self, VOCAB_SIZE, block_size, embed_dim, hidden_size):
super().__init__()
self.embedding = nn.Embedding(VOCAB_SIZE, embed_dim)
self.hidden = nn.Linear(block_size * embed_dim, hidden_size)
self.output = nn.Linear(hidden_size, VOCAB_SIZE)
def forward(self, X):
emb = self.embedding(X)
emb = emb.view(X.shape[0], -1)
h = torch.tanh(self.hidden(emb))
return self.output(h)
However, this model still has an important limitation: the context length is fixed. If block_size = 3, the model can only use the last three characters, even if longer-range information would be useful. Increasing the context size helps, but it also introduces side-effects. To see the issue more clearly and summerize this section, let us compare the models we have built so far.
A bigram model uses only the current character to predict the next one. In other words, it assumes that the future depends only on one previous token. This is extremely restrictive. It can capture local transition tendencies, but it cannot represent longer patterns. A neural n-gram model is more expressive because it uses a window of several previous characters. This is an improvement, but the context length is still fixed in advance which creates several problems:
- If the useful information lies outside the chosen window, the model simply cannot use it.
- If we increase
block_size, the input becomes larger, the number of parameters grows, and the model becomes harder to train efficiently. - The model always expects the same number of previous tokens, even though real sequences may require short or long context depending on the situation.
- The model does not carry forward a learned summary of the past. Instead, it repeatedly rebuilds its prediction from a fixed slice of recent tokens.
This motivates a more flexible approach where the model can use information from arbitrarily long sequences.
Latent Autoregressive Modeling¶
We had previously demonstrated the problems multi-step prediction, which illustrated a key weakness of fixed-window autoregressive models. They rely only on the last $\tau$ observations and have no mechanism for maintaining a richer summary of the longer history. As a result, they may perform reasonably well for short-horizon prediction while struggling in longer recursive forecasts. One possible alternative is to maintain a latent (hidden) state that summarizes the past. Instead of explicitly storing the last $\tau$ observations, the model updates an internal representation as new data arrives. We can imagine a hidden state that evolves over time:
$$ h_t = f(x_t, h_{t-1}). $$
The vector $h_t$ acts as a compact summary of everything the model has seen so far. Rather than conditioning predictions directly on the entire history, we instead condition on this latent representation:
$$ P(x_t \mid h_{t-1}). $$
This idea allows the model to process sequences of arbitrary length while keeping the number of parameters fixed. Instead of growing the input size with time, the model continually updates a fixed-size internal state that carries information about the past. To illustrate the idea of a latent state, consider the following update rule:
$$ h_t = \tanh(x_t W_{xh} + h_{t-1} W_{hh} + b_h). $$
Here, the vector $x_t$ represents the current observation at time $t$ (for example the current price of a financial index). The matrix $W_{xh}$ determines how the current observation influences the latent state. It maps the input into the hidden representation.
The vector $h_{t-1}$ represents the previous latent state. It summarizes everything the model has seen up to time $t-1$. The matrix $W_{hh}$ determines how this previous state influences the next state. In other words, it controls how information from the past is carried forward through time. At each time step the model combines two sources of information: the current observation and the previous latent state. The resulting vector $h_t$ becomes a compact summary of the history seen so far.
Important
The $\tanh$ nonlinearity is often used in latent state updates because it produces outputs in the interval $[-1,1]$. This is important because the hidden state update is applied repeatedly as the sequence is processed. If the activation function allows values to grow without bound, the hidden state may gradually drift to very large magnitudes as these updates accumulate. The $\tanh$ function keeps the state within a fixed range while still allowing both positive and negative values. This makes it easier for the model to represent increases and decreases in the latent representation relative to the previous state.
Other common nonlinearities are less suitable for this type of repeated state update. A sigmoid activation restricts the state to the interval $[0,1]$. This prevents the representation from taking negative values and tends to push the state toward the extremes of the interval when the input becomes large. In these saturated regions the gradient becomes very small, making learning difficult. On the other hand, ReLU outputs values in $[0,\infty)$, the hidden state is unbounded above. When the update rule is applied repeatedly, positive values may accumulate and grow over time. In addition, negative inputs are mapped to zero, which can erase information carried by the state.
Recurrent Neural Networks¶
Info
The following source was consulted in preparing this material: Zhang, A., Lipton, Z. C., Li, M., & Smola, A. J. Dive into Deep Learning. Cambridge University Press. Chapter 10: Modern Recurrent Neural Networks.
A neural network that implements this latent autoregressive formulation above is called a recurrent neural network (RNN). A RNN specifies the function $f$ as a parametric neural network. At each step, the model combines the current input $x_t$ and the previous hidden state $h_{t-1}$. The result is a new hidden state $h_t$, which becomes the input to the next step. We are basically modeling
$$ P(x_t \mid x_{t-1}, \dots, x_1) \approx P(x_t \mid h_{t-1}), $$
where the hidden state acts as a summary of the past. To produce predictions, we introduce an output mapping from the hidden state:
$$ o_t = h_t W_{hy} + b_y. $$
Here, $W_{hy}$ maps the latent representation to the output space, and $b_y$ is a bias term. The vector $o_t$ represents unnormalized scores (logits) for the next observation.
Note
Note that the choice of the function $f$ is not fixed. In principle, any sufficiently expressive function could be used to combine $x_t$ and $h_{t-1}$. The chosen function is simply the most basic and widely used choice: a linear transformation followed by tanh nonlinearity. It is easy to compute, differentiable, and allows the model to be trained efficiently using gradient-based methods.
Also note that the same parameters are reused at every time step. The matrices $W_{xh}$, $W_{hh}$, and $W_{hy}$ do not depend on $t$. As a result, the number of parameters remains fixed even as the sequence length grows.

{kind=link}
PAD_IDX = VOCAB_SIZE # unique number not corresponding to any character
RNN_VOCAB_SIZE = VOCAB_SIZE + 1
def build_rnn_dataset(words, block_size=6):
X, Y = [], []
for w in words:
seq = [stoi['.']] + [stoi[ch] for ch in w] + [stoi['.']]
x = seq[:-1]
y = seq[1:]
if len(x) > block_size:
x = x[:block_size]
y = y[:block_size]
else:
pad = block_size - len(x)
x = x + [PAD_IDX] * pad
y = y + [PAD_IDX] * pad
X.append(x)
Y.append(y)
return torch.tensor(X), torch.tensor(Y)
The dataset construction must change when moving from a neural n-gram model to an RNN. In the neural n-gram setting, each training example consists of a fixed-length context and a single target. The model receives a block of previous tokens and predicts the next one. This leads to data of the form $$ X \in \mathbb{R}^{N \times \tau}, \quad Y \in \mathbb{R}^{N}, $$ where $\tau$ is the context length. In an RNN, the model processes an entire sequence step by step and produces a prediction at every time step. As a result, each training example must contain both the input sequence and the corresponding sequence of targets: $$ X \in \mathbb{R}^{N \times T}, \quad Y \in \mathbb{R}^{N \times T}. $$
Each row in $X$ is a sequence of tokens, and the corresponding row in $Y$ is the same sequence shifted by one position. This aligns with the recurrent computation: at time step $t$, the model receives $x_t$ and is trained to predict $x_{t+1}$. The main difference is that we no longer construct independent input–target pairs for each position. Instead, we treat the entire sequence as a chain of predictions, allowing the hidden state to carry information across time. This change is necessary because the RNN does not rely on an a fixed context, it builds its own representation of the past through the evolving hidden state.
Sequences in real data do not all have the same length. For example, after adding boundary tokens we may have
emma → [., e, m, m, a, .]
olivia → [., o, l, i, v, i, a, .]
These sequences differ in length, but when we train neural networks we process data in batches. This means we must represent multiple sequences together in a single tensor. However, tensor operations require consistent dimensions, so we must enforce a fixed length $T$ for all sequences: $$ X \in \mathbb{R}^{B \times T}. $$
This requirement does not arise in the neural n-gram model, because each example already has fixed size $\tau$ by construction. In contrast, the RNN does not use fixed contexts, it operates over full sequences, and therefore we must explicitly align those sequences to a common length. Padding is the mechanism that achieves this alignment. We take shorter sequences and extend them with a special token (for example 0) until they match the chosen length $T$. For instance, if we fix $T = 6$, then
X1: [., e, m, m, a] → [., e, m, m, a, .]
X2: [., o, l, i, v, i] → [., o, l, i, v, i]
and the corresponding targets become
Y1: [e, m, m, a, ., 0]
Y2: [o, l, i, v, i, a]
Now both sequences have the same length and can be stacked into a single batch. The reason this is specifically necessary for RNNs lies in how the computation proceeds. An RNN processes sequences step by step across time. At each time step $t$, it expects an input $x_t$ for every sequence in the batch, and updates the hidden state accordingly. This means that all sequences must be defined for all time steps $t = 1, \dots, T$. Without padding, shorter sequences would simply not have values for later time steps, and the computation would not be well-defined.
Note
Padding introduces artificial tokens that do not correspond to real data. These positions should not influence learning. In practice, we either ignore them when computing the loss or rely on the model to learn that they carry no meaningful information. The key point is that padding is not a modeling choice but a computational necessity. The RNN itself can handle variable-length dependencies through its hidden state, but batching requires us to represent those sequences in a uniform tensor.
class RNN(nn.Module):
def __init__(self, VOCAB_SIZE, embed_dim, hidden_size):
super().__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(VOCAB_SIZE, embed_dim)
self.W_xh = nn.Parameter(torch.randn(embed_dim, hidden_size) * 0.01)
self.W_hh = nn.Parameter(torch.randn(hidden_size, hidden_size) * 0.01)
self.b_h = nn.Parameter(torch.zeros(hidden_size))
self.W_hy = nn.Parameter(torch.randn(hidden_size, VOCAB_SIZE) * 0.01)
self.b_y = nn.Parameter(torch.zeros(VOCAB_SIZE))
def forward(self, X, h=None):
B, T = X.shape # batch and time step dimensions
emb = self.embedding(X)
# initializing hidden state in the first time step
if h is None:
h = torch.zeros(B, self.hidden_size)
outputs = []
for t in range(T):
x_t = emb[:, t]
h = torch.tanh(x_t @ self.W_xh + h @ self.W_hh + self.b_h)
out = h @ self.W_hy + self.b_y
outputs.append(out)
logits = torch.stack(outputs, dim=1)
return logits, h
The model will produce logits of shape $(B, T, V)$, where $B$ is the batch size, $T$ is the sequence length, and $V$ is the vocabulary size. For every sequence in the batch and every time step, the model outputs a score for each possible next character. The targets have shape $(B, T)$, since at each position we only need the index of the correct next character.
To train the model, we compare the predicted logits against the true next-character indices using the cross-entropy loss. Since torch.nn.functional.cross_entropy expects inputs of shape $(N, V)$ and targets of shape $(N)$, we flatten the batch and time dimensions together. In other words, we compute the average negative log-likelihood over all positions in the batch. The model is penalized whenever it assigns low probability to the correct next character. We should know that minimizing this loss is equivalent to maximizing the likelihood of the training sequences under the model.
BLOCK_SIZE = 10
BATCH_SIZE = 64
EMBED_DIM = 2
HIDDEN_SIZE = 128
words = load_names('makemore')
X, Y = build_rnn_dataset(words, block_size=BLOCK_SIZE)
X.shape, Y.shape
(torch.Size([32033, 10]), torch.Size([32033, 10]))
X[:5, :5], Y[:5, :5]
(tensor([[ 0, 5, 13, 13, 1],
[ 0, 15, 12, 9, 22],
[ 0, 1, 22, 1, 27],
[ 0, 9, 19, 1, 2],
[ 0, 19, 15, 16, 8]]),
tensor([[ 5, 13, 13, 1, 0],
[15, 12, 9, 22, 9],
[ 1, 22, 1, 0, 27],
[ 9, 19, 1, 2, 5],
[19, 15, 16, 8, 9]]))
model = RNN(
VOCAB_SIZE=RNN_VOCAB_SIZE,
embed_dim=EMBED_DIM,
hidden_size=HIDDEN_SIZE,
)
lr = 0.005
epochs = 10000
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
for epoch in range(epochs):
Xb, Yb = sample_batch(X, Y, BATCH_SIZE)
logits, h = model(Xb)
B, T, V = logits.shape
loss = F.cross_entropy(
logits.reshape(B * T, V),
Yb.reshape(B * T),
ignore_index=PAD_IDX,
)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
if (epoch + 1) % (epochs // 10) == 0:
print(f'{epoch+1}/{epochs} | loss: {loss.item():.4f}')
1000/10000 | loss: 2.2407 2000/10000 | loss: 2.0975 3000/10000 | loss: 2.1060 4000/10000 | loss: 2.1770 5000/10000 | loss: 2.1027 6000/10000 | loss: 2.1206 7000/10000 | loss: 2.1420 8000/10000 | loss: 2.1225 9000/10000 | loss: 2.0672 10000/10000 | loss: 2.0353
Gradient Clipping¶
When training an RNN, gradients are propagated through many time steps. During backpropagation through time, the same parameters (especially $W_{hh}$) are applied repeatedly. As a result, gradients involve products of many Jacobians. This leads to exploding and vanishing gradients. The gradient with respect to a hidden state at time $t$ is
$$ \frac{\partial \mathcal{L}}{\partial h_t} = \frac{\partial \mathcal{L}}{\partial h_T} \prod_{k=t+1}^{T} \frac{\partial h_k}{\partial h_{k-1}}. $$
This shows that the gradient is a product of many Jacobian matrices. If these matrices tend to have norms greater than $1$, the product grows exponentially → exploding gradients. If they are less than $1$, the product shrinks exponentially → vanishing gradients. To see this more clearly, consider a simplified recurrence without nonlinearity:
$$ h_t = W_{hh} h_{t-1}. $$
Then
$$ h_t = W_{hh}^t h_0. $$
Repeated multiplication by $W_{hh}$ amplifies or shrinks vectors depending on its scaling behavior. For example, if eigenvalues or singular values are $> 1$, values grow exponentially; if they are $< 1$, they decay. In real RNNs, we also have nonlinearities:
$$ h_t = \tanh(W_{xh}x_t + W_{hh}h_{t-1} + b). $$
The Jacobian becomes
$$ \frac{\partial h_t}{\partial h_{t-1}} = \operatorname{diag}(\tanh'(a_t)) , W_{hh}. $$
Since $\tanh'(a) \le 1$, the activation typically shrinks gradients, making vanishing gradients common. At the same time, if $W_{hh}$ is large enough, it can still cause explosion. Therefore, both problems can occur simultaneously in different regimes.
Gradient clipping is designed specifically to address exploding gradients. It does not change the forward computation and does not fix vanishing gradients. It only limits how large gradients can become during backpropagation. The most common method is norm clipping:
$$ g \leftarrow g \cdot \frac{\text{max\_norm}}{\max(\|g\|, \text{max\_norm})} $$
Here, $g$ is the gradient vector and $|g|$ is its norm. If the gradient norm exceeds a threshold (e.g. $1.0$), it is scaled down to that threshold while preserving its direction. Without clipping, large gradients lead to very large parameter updates, causing instability or divergence. With clipping, gradients are bounded, so updates remain controlled and training stays stable.
Note
Important: clipping prevents explosion but does not solve vanishing gradients. Vanishing gradients require different solutions (e.g. gating mechanisms such as LSTM/GRU or architectural changes, which will soon be discussed).
model.eval()
max_len = 10 # to prevent generating very long samples
names = []
with torch.no_grad():
for _ in range(num_samples):
h = None
ix = torch.tensor([[stoi['.']]])
out = []
for _ in range(max_len):
logits, h = model(ix, h)
probs = torch.softmax(logits[:, -1, :], dim=-1)
probs[0, PAD_IDX] = 0
probs = probs / probs.sum(dim=-1, keepdim=True)
ix = torch.multinomial(probs, num_samples=1)
next_ix = ix.item()
if next_ix == stoi['.']:
break
out.append(itos[next_ix])
names.append(''.join(out))
names
['neva', 'fynley', 'breaz', 'cireth', 'gedley', 'rigvin', 'mariye', 'alena', 'pestere', 'cendley']
Backpropagation Through Time¶
Recurrent Neural Networks process sequences step by step, maintaining a hidden state that carries information forward in time. At each time step $t$, the model updates its hidden state and produces an output:
$$ h_t = \tanh(W_{xh}x_t + W_{hh}h_{t-1} + b), \quad y_t = W_{hy}h_t. $$
Unlike feedforward networks, the same parameters ($W_{xh}, W_{hh}, W_{hy}$) are reused at every time step. This parameter sharing is what allows RNNs to model sequences, but it also requires a special training procedure: backpropagation through time (BPTT).
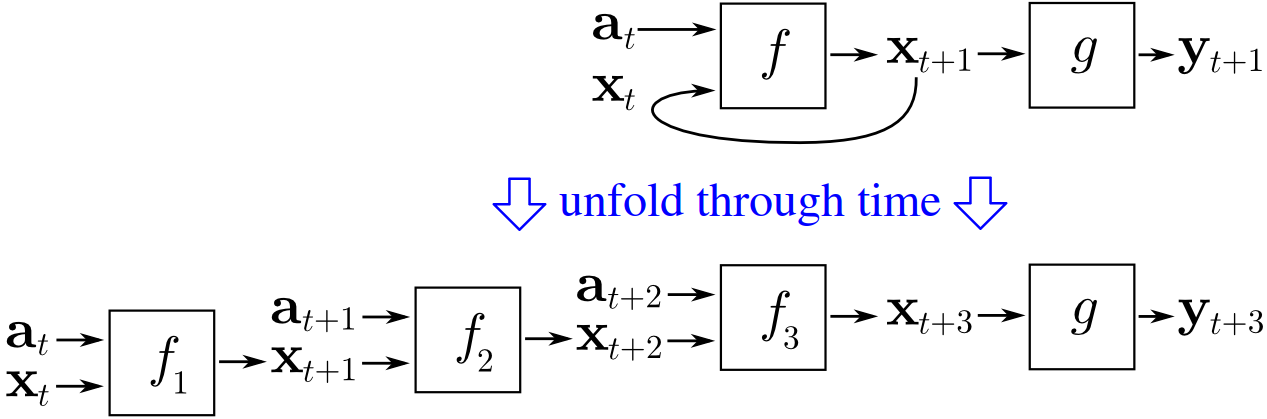
The key idea of BPTT is to unroll the RNN across time and treat it as a deep feedforward network where each layer corresponds to one time step. For a sequence of length $T$, the network becomes a chain of $T$ repeated computations with shared weights. The total loss over the sequence is typically
$$ \mathcal{L} = \sum_{t=1}^{T} \mathcal{L}_t, $$
where $\mathcal{L}_t$ is the loss at time step $t$. To compute gradients, we apply the chain rule through this unrolled structure. The gradient with respect to parameters (e.g. $W_{hh}$) accumulates contributions from all time steps:
$$ \frac{\partial \mathcal{L}}{\partial W_{hh}} = \sum_{t=1}^{T} \frac{\partial \mathcal{L}}{\partial h_t} \frac{\partial h_t}{\partial W_{hh}}. $$
However, each $\frac{\partial \mathcal{L}}{\partial h_t}$ depends on all future time steps, since $h_t$ influences $h_{t+1}, h_{t+2}, \dots, h_T$. This gives
$$ \sum_{k=t}^{T} \frac{\partial \mathcal{L}*k}{\partial h_k} \prod*{j=t+1}^{k} \frac{\partial h_j}{\partial h_{j-1}}. $$
Once again, the expression demonstrates the core difficulty of BPTT: gradients involve products of many Jacobians across time, causing exploding/vanishing gradient problems. A common practical variant of BPTT is truncated BPTT, where backpropagation is limited to a fixed number of time steps (e.g. 20–100). Instead of propagating gradients through the entire sequence, we stop after a window of length $K$:
$$ \frac{\partial \mathcal{L}}{\partial h_t} \approx \frac{\partial \mathcal{L}}{\partial h_{t+K}} \prod_{j=t+1}^{t+K} \frac{\partial h_j}{\partial h_{j-1}}. $$
This reduces computational cost and mitigates instability, but it limits the model's ability to learn very long-range dependencies.
Long Short-Term Memory¶
The vanilla RNN introduced an important idea: instead of rebuilding the prediction from a fixed window, we maintain a hidden state that is updated over time. This already gives the model a form of memory. However, in practice, vanilla RNNs have a serious weakness. When sequences become long, they struggle to preserve useful information over many time steps. The hidden state is repeatedly transformed by the same recurrent update, so gradients may shrink or grow too much during backpropagation. Gradient clipping can help with exploding gradients, but vanishing gradients require a more definitive solution.
The main idea of Long Short-Term Memory (LSTM) is simple: instead of storing everything inside a single repeatedly overwritten hidden state, we introduce a more carefully controlled memory. The model learns when to write new information, when to keep old information, and when to expose stored information to the rest of the network. In other words, the model does not merely update its state at every step. It learns how much it should update it.
The name long short-term memory reflects two kinds of storage. As before, the model has trainable weights, which encode long-term statistical knowledge gathered during training. It also has activations that move from one step to the next, which provide short-term dynamic context for a specific sequence. LSTM adds an intermediate memory cell whose content can be preserved much more reliably across time. Rather than forcing the model to rewrite its entire representation at each step, LSTM allows it to keep certain information nearly unchanged for many steps and modify it only when needed.
To make this possible, LSTM introduces gates. A gate is a learned mechanism that outputs values between $0$ and $1$, typically using the sigmoid function. Values close to $0$ basically mean "block this information" and values close to $1$ mean "allow this information to pass." Since these gate values are produced from the current input and the previous hidden state, the model can decide dynamically, at each time step, how information should flow.

{kind=link}
There are three gates in a standard LSTM. The input gate controls how much new candidate information should be written into memory. The forget gate controls how much of the previous memory should be kept. The output gate controls how much of the internal memory should be revealed as the hidden state. Suppose the input at time step $t$ is $x_t$, the previous hidden state is $h_{t-1}$, and the previous cell state is $c_{t-1}$. Then the three gates are computed as
$$ i_t = \sigma(x_t W_{xi} + h_{t-1} W_{hi} + b_i), $$
$$ f_t = \sigma(x_t W_{xf} + h_{t-1} W_{hf} + b_f), $$
$$ o_t = \sigma(x_t W_{xo} + h_{t-1} W_{ho} + b_o). $$
Here, $i_t$ is the input gate, $f_t$ is the forget gate, and $o_t$ is the output gate. Each is a vector, not a single number. This means the model can decide separately for each hidden dimension how much to remember, forget, or reveal. In addition to the gates, the LSTM computes a candidate content vector, often written as
$$ \tilde{c}_t = \tanh(x_t W_{xc} + h_{t-1} W_{hc} + b_c). $$
This is the new information that could be written into memory. However, it is not written directly. First, the input gate decides how much of this candidate should actually enter the cell state. The core of the LSTM is the cell state update:
$$ c_t = f_t \odot c_{t-1} + i_t \odot \tilde{c}_t. $$
This equation is the heart of the architecture. The previous memory $c_{t-1}$ is multiplied elementwise by the forget gate $f_t$, so the model can keep it, partially erase it, or completely remove it. At the same time, the candidate memory $\tilde{c}_t$ is multiplied by the input gate $i_t$, so the model can decide how much new information to write. The new cell state $c_t$ is therefore not a complete overwrite. It is a controlled combination of retained old information and selected new information.
In a vanilla RNN, the hidden state is repeatedly transformed through a nonlinear mapping, which tends to distort or wash out older information. In an LSTM, the cell state has a more direct path across time. If the forget gate stays close to $1$ and the input gate stays close to $0$, then the memory can remain almost unchanged across many steps:
$$ c_t \approx c_{t-1}. $$
This creates a route through time along which information and gradients can pass much more easily. The model is no longer forced to rewrite everything at every step. Finally, the hidden state is computed from the cell state using the output gate:
$$ h_t = o_t \odot \tanh(c_t). $$

{kind=link}
This means the internal memory and the exposed hidden state are not the same thing. The cell state $c_t$ is the long-lived internal memory. The hidden state $h_t$ is the controlled visible representation that gets passed to the next layer or used for prediction. This distinction is essential. The model may store information internally for a long time without revealing all of it at every step. Only when the output gate opens does that stored information strongly affect the external computation. So the LSTM maintains two state variables instead of one:
$$ (h_t, c_t). $$
The hidden state $h_t$ is the exposed working state, while the cell state $c_t$ is the protected internal memory. This gives the model much finer control over information flow than a vanilla RNN.
Note
At an intuitive level, the LSTM update can be read as follows. First, decide what old information should be forgotten. Second, decide what new information should be written. Third, update the internal memory. Fourth, decide how much of that memory should be exposed as the hidden state. This sequence of operations makes LSTM much more stable and expressive for long sequential problems than a standard recurrent network.
We now translate the LSTM equations directly into code, in a similar vein as RNN. The implementation below is written manually rather than using nn.LSTM, so that each we see how LSTM works under the hood.
class LSTM(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_size):
super().__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(vocab_size, embed_dim)
# input gate parameters
self.W_xi = nn.Parameter(torch.randn(embed_dim, hidden_size) * 0.01)
self.W_hi = nn.Parameter(torch.randn(hidden_size, hidden_size) * 0.01)
self.b_i = nn.Parameter(torch.zeros(hidden_size))
# forget gate parameters
self.W_xf = nn.Parameter(torch.randn(embed_dim, hidden_size) * 0.01)
self.W_hf = nn.Parameter(torch.randn(hidden_size, hidden_size) * 0.01)
self.b_f = nn.Parameter(torch.zeros(hidden_size))
# output gate parameters
self.W_xo = nn.Parameter(torch.randn(embed_dim, hidden_size) * 0.01)
self.W_ho = nn.Parameter(torch.randn(hidden_size, hidden_size) * 0.01)
self.b_o = nn.Parameter(torch.zeros(hidden_size))
# cell state parameters
self.W_xc = nn.Parameter(torch.randn(embed_dim, hidden_size) * 0.01)
self.W_hc = nn.Parameter(torch.randn(hidden_size, hidden_size) * 0.01)
self.b_c = nn.Parameter(torch.zeros(hidden_size))
# output parameters
self.W_hy = nn.Parameter(torch.randn(hidden_size, vocab_size) * 0.01)
self.b_y = nn.Parameter(torch.zeros(vocab_size))
def forward(self, X, h=None, c=None):
B, T = X.shape
emb = self.embedding(X)
if h is None:
h = torch.zeros(B, self.hidden_size)
if c is None:
c = torch.zeros(B, self.hidden_size)
outputs = []
for t in range(T):
x_t = emb[:, t]
i_t = torch.sigmoid(x_t @ self.W_xi + h @ self.W_hi + self.b_i)
f_t = torch.sigmoid(x_t @ self.W_xf + h @ self.W_hf + self.b_f)
o_t = torch.sigmoid(x_t @ self.W_xo + h @ self.W_ho + self.b_o)
c_t = torch.tanh(x_t @ self.W_xc + h @ self.W_hc + self.b_c)
c = c*f_t + i_t*c_t
h = o_t * torch.tanh(c)
out = h @ self.W_hy + self.b_y
outputs.append(out)
logits = torch.stack(outputs, dim=1)
return logits, h, c
In the mathematical formulation, we used explicit time indices such as $h_t$ and $c_t$ to emphasize that the hidden state and cell state evolve over time. In the implementation, however, we write simply h and c. Inside the loop over time steps, the variables h and c always represent the current state. At the beginning of an iteration, h corresponds to $h_{t-1}$ and c corresponds to $c_{t-1}$. After applying the update equations, they are overwritten to become $h_t$ and $c_t$. We also slightly adjust the notation for the candidate memory. In the derivation, this quantity is often written as $\tilde{c}_t$ to distinguish it from the actual cell state. In code, we denote it as c_t for simplicity. This should be interpreted as the candidate update, not the final cell state.
Exercise
Initialize and train an LSTM model and sample names from it.
Gated Recurrent Unit¶
The LSTM introduced a powerful idea: instead of blindly updating a hidden state at every step, the model learns to control information flow through gates. However, this flexibility comes at a cost. The LSTM maintains two separate states ($h_t$ and $c_t$) and uses three gates, which increases both the number of parameters and computational complexity.
The Gated Recurrent Unit (GRU) simplifies this design while preserving the essential idea of gated information flow. Instead of maintaining a separate cell state, the GRU merges memory and hidden representation into a single state. At the same time, it reduces the number of gates from three to two. Despite this simplification, GRUs often achieve performance comparable to vanilla LSTMs in practice.

{kind=link}
The GRU introduces two gates: the reset gate and the update gate. As in LSTMs, these gates use sigmoid activations and take values in the interval $[0,1]$, allowing the model to control how information flows through time. Let $x_t$ denote the input at time step $t$ and $h_{t-1}$ the previous hidden state. The reset gate $r_t$ and update gate $z_t$ are computed as
$$ r_t = \sigma(x_t W_{xr} + h_{t-1} W_{hr} + b_r), $$
$$ z_t = \sigma(x_t W_{xz} + h_{t-1} W_{hz} + b_z). $$
The reset gate determines how much of the previous state should be used when computing new information. If $r_t$ is close to $0$, the model effectively ignores the past state. If it is close to $1$, the past is fully taken into account. Next, the model computes a candidate hidden state $\tilde{h}_t$:
$$ \tilde{h}_t = \tanh(x_t W_{xh} + (r_t \odot h_{t-1}) W_{hh} + b_h). $$
This equation is similar to the vanilla RNN update, with one important difference: the previous hidden state is first modulated by the reset gate. When $r_t$ is small, the contribution of $h_{t-1}$ is suppressed, and the candidate becomes largely a function of the current input. This allows the model to "reset" its memory when past information is no longer relevant. Finally, the update gate determines how the new hidden state is formed:
$$ h_t = z_t \odot h_{t-1} + (1 - z_t) \odot \tilde{h}_t. $$
This is a convex combination between the previous state and the candidate state. When $z_t$ is close to $1$, the model keeps the old state and ignores the candidate. This allows information to persist across many time steps without modification. When $z_t$ is close to $0$, the model replaces the old state with the newly computed candidate. This update plays a role similar to the cell state in LSTMs. Instead of explicitly maintaining a separate memory vector, the GRU uses the update gate to control how much of the past is carried forward. As a result, the GRU can preserve information over long sequences while using a simpler structure.
Note
Intuitively, the GRU update can be read as follows. First, decide how much of the past should influence the new information (reset gate). Then compute a candidate representation. Finally, decide how much of the old state should be kept versus replaced (update gate).
class GRU(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_size):
super().__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.W_xr = nn.Parameter(torch.randn(embed_dim, hidden_size) * 0.01)
self.W_hr = nn.Parameter(torch.randn(hidden_size, hidden_size) * 0.01)
self.b_r = nn.Parameter(torch.zeros(hidden_size))
self.W_xz = nn.Parameter(torch.randn(embed_dim, hidden_size) * 0.01)
self.W_hz = nn.Parameter(torch.randn(hidden_size, hidden_size) * 0.01)
self.b_z = nn.Parameter(torch.zeros(hidden_size))
self.W_xh = nn.Parameter(torch.randn(embed_dim, hidden_size) * 0.01)
self.W_hh = nn.Parameter(torch.randn(hidden_size, hidden_size) * 0.01)
self.b_h = nn.Parameter(torch.zeros(hidden_size))
self.W_hy = nn.Parameter(torch.randn(hidden_size, vocab_size) * 0.01)
self.b_y = nn.Parameter(torch.zeros(vocab_size))
def forward(self, X, h=None):
B, T = X.shape
emb = self.embedding(X)
if h is None:
h = torch.zeros(B, self.hidden_size)
outputs = []
for t in range(T):
x_t = emb[:, t]
r_t = torch.sigmoid(x_t @ self.W_xr + h @ self.W_hr + self.b_r)
z_t = torch.sigmoid(x_t @ self.W_xz + h @ self.W_hz + self.b_z)
h_t = torch.tanh(x_t @ self.W_xh + (r_t * h) @ self.W_hh + self.b_h)
h = z_t * h + (1 - z_t) * h_t
out = h @ self.W_hy + self.b_y
outputs.append(out)
logits = torch.stack(outputs, dim=1)
return logits, h
Exercise
Initialize and train a GRU model and sample names from it.
Deep and Bidirectional Recurrent Networks¶
So far, we have improved recurrent models by changing how a single layer processes information over time (e.g. LSTM and GRU). There are also architectural extensions that do not modify the core update rule, but instead change how recurrent layers are organized or how information flows through the sequence.
A deep RNN is obtained by stacking multiple recurrent layers on top of each other. At each time step, the input is first processed by the lowest layer, and its output is then passed to the next layer, and so on. Each layer maintains its own hidden state and learns its own transformation. This introduces depth in the vertical direction, in addition to the existing depth across time. Lower layers may learn simple local patterns, while higher layers can build more abstract representations from them. This is similar in spirit to deep feedforward networks. In practice, they are harder to train and require careful tuning, and most of the improvement in recurrent models historically comes from gating mechanisms (LSTM, GRU) rather than depth itself.
Standard recurrent models process sequences in a single direction, typically from left to right. This means that the representation at a given position depends only on past inputs. A bidirectional RNN removes this limitation by processing the sequence in both directions. One recurrent network runs forward (from beginning to end), while another runs backward (from end to beginning). The representations from both directions are then combined at each time step. This allows the model to use both past and future context. In many tasks, such as text classification or sequence labeling, the meaning of an element depends not only on what came before it, but also on what comes after it. The main limitation is that bidirectional models require access to the entire sequence. They cannot be used in settings where predictions must be made step by step, such as autoregressive generation.
Machine Translation¶
So far, our sequence models predicted the next token inside a single sequence. Machine translation is different. Here, the model receives a sequence in one language and must generate a corresponding sequence in another language. This immediately makes the problem harder for two reasons. First, the input and output lengths are generally different. Second, the two sequences are not positionally aligned: the $t$-th word in the source does not necessarily correspond to the $t$-th word in the target, because different languages organize meaning differently. Word order, morphology, and even what must be said explicitly can vary across languages.
This is one instance of a broader class of problems called sequence-to-sequence (seq2seq) problems. In such tasks, we map one variable-length sequence to another variable-length sequence. Machine translation is a major example, but the same general structure appears in dialogue systems, question answering, summarization, speech recognition, and many other settings where the output is itself a sequence rather than a single label. It is useful to contrast this with language modeling. In language modeling, we estimate probabilities like $$ P(x_1, x_2, \dots, x_T) \quad\text{or}\quad P(x_t \mid x_1, \dots, x_{t-1}), $$ so the model stays within one sequence and predicts its continuation. In machine translation, instead, we want a conditional sequence model: $$ P(y_1, y_2, \dots, y_{T'} \mid x_1, x_2, \dots, x_T), $$ where the source sequence $x_{1:T}$ and the target sequence $y_{1:T'}$ may have different lengths. The task is therefore not merely to continue a sequence, but to transform one sequence into another under a learned conditional distribution. To study this setting, we use a bilingual English--Azerbaijani dataset consisting of sentence pairs. Each example has a source sentence in English and a target sentence in Azerbaijani. At the raw text level, each line contains two text sequences separated by a tab. Conceptually, the dataset looks like this:
| source | target |
|---|---|
go . |
get . |
hi . |
salam . |
who ? |
kim ? |
Before a neural model can use these sentence pairs, the text must be standardized. A few preprocessing steps are important. We convert text to lowercase, replace special spacing characters with ordinary spaces, and separate punctuation marks from words. This last step matters because we want punctuation such as ., !, and ? to become individual tokens. For example, go. becomes go . rather than remaining a single merged token. This makes tokenization more regular and reduces sparsity. We will now load our dataset from bilingual tatoeba project which provides parallel translation entries for many languages.
from pathlib import Path
def load_dataset(path, limit=None):
text = Path(path).read_text(encoding="utf-8")
pairs = []
for l in text.splitlines():
if "\t" not in l:
continue
s = l.split("\t")
src, tgt = s[0].strip(), s[1].strip()
if src and tgt:
pairs.append((src, tgt))
if limit and len(pairs) >= limit:
break
return pairs
from IPython.display import Markdown
# Download the needed tatoeba dataset from https://www.manythings.org/anki
DATA_PATH = "./data/aze-eng/aze.txt"
# DATA_PATH = "aze.txt"
pairs = load_dataset(DATA_PATH, limit=5000)
table = "\n".join(f"| `{s}` | `{t}` |" for s, t in pairs[:5])
Markdown(f"""
| source | target |
|---|---|
{table}
""")
| source | target |
|---|---|
Go. |
Get. |
Run. |
Qaç. |
Run. |
Qaçın. |
Who? |
Kim? |
Stay. |
Qal. |
Unlike the earlier character-level language modeling section, here we use word-level tokenization. That means each sequence becomes a list of words and punctuation tokens rather than a list of characters. For instance, go . becomes ['go', '.', '<eos>'], and salam ! becomes ['salam', '!', '<eos>']. We append the special token <eos> (end of sequence) to every sentence. This token is crucial in sequence generation: when the decoder eventually predicts <eos>, it signals that the output sequence is complete. This is similar to . that we have been using in character-level tokenization. At this point, each example consists of two tokenized sequences:
$$
(x_1, x_2, \dots, x_T, \texttt{<eos>})
\quad\text{and}\quad
(y_1, y_2, \dots, y_{T'}, \texttt{<eos>}).
$$
Notice again that $T$ and $T'$ need not be equal. This is the main difficulty of sequence-to-sequence learning. Neural networks, however, process minibatches most efficiently when tensors have uniform shape. Therefore, even though sentences naturally have variable length, we usually choose a fixed maximum number of time steps, often denoted num_steps. If a sequence is shorter than this length, we pad it with the special token <pad>. If it is longer, we truncate it. This is not a modeling assumption about language itself, it is mainly a computational device that allows us to stack many examples into tensors of the same shape.
So if num_steps = 9, a source sentence such as ['hi', '.', '<eos>'] becomes ['hi', '.', '<eos>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>']. In practice, we also keep track of the valid length, i.e. the number of real tokens excluding <pad>. This becomes important later, because some models should ignore the padding positions when computing internal representations or attention weights.
import re
def preprocess(text):
text = text.lower()
text = text.replace("\u202f", " ").replace("\xa0", " ")
text = re.sub(r"([,.!?])", r" \1", text)
return text.strip()
def process_pair(src, tgt):
src_tokens = preprocess(src).split() + ["<eos>"]
tgt_tokens = preprocess(tgt).split() + ["<eos>"]
tgt_input = ["<bos>"] + tgt_tokens
labels = tgt_tokens + ["<pad>"]
return src_tokens, tgt_tokens, tgt_input, labels
processed = [process_pair(s, t) for s, t in pairs]
processed[0]
(['go', '.', '<eos>'], ['get', '.', '<eos>'], ['<bos>', 'get', '.', '<eos>'], ['get', '.', '<eos>', '<pad>'])
Because the source and target languages are different, we build two separate vocabularies, one for English and one for Azerbaijani. This is necessary because the token sets, frequencies, and meanings differ across languages. As before, special tokens are added to the vocabulary. In this setting, the important ones are:
<pad>for padding shorter sequences,<eos>for marking the end of a sequence,<unk>for rare or unseen tokens,<bos>for the beginning of the target sequence during decoding.
The <bos> token deserves special attention. In target-side training, the decoder does not start from nothing. It needs an initial input token, and that role is played by <bos>. So if the target sentence is ['salam', '.', '<eos>'], the decoder input becomes ['<bos>', 'salam', '.', '<eos>'], while the supervision labels become ['salam', '.', '<eos>', '<pad>'] after alignment to the chosen length. In other words, the decoder is trained to predict the next target token from the previous target tokens. This is exactly the same autoregressive principle as in language modeling, except now it is conditioned on the source sentence as well.
def build_vocab(sequences, min_freq=1):
counter = Counter(token for seq in sequences for token in seq)
stoi = {"<pad>": 0, "<bos>": 1, "<eos>": 2, "<unk>": 3}
for token, freq in counter.items():
if freq >= min_freq and token not in stoi:
stoi[token] = len(stoi)
itos = {i: t for t, i in stoi.items()}
return stoi, itos
def encode(seq, stoi):
return [stoi.get(token, stoi["<unk>"]) for token in seq]
def decode(seq, itos):
return [itos.get(i, "<unk>") for i in seq]
def pad(seq, max_len, pad_idx):
return seq[:max_len] + [pad_idx] * max(0, max_len - len(seq))
src_seqs = [s for s, _, _, _ in processed]
tgt_seqs = [t for _, t, _, _ in processed]
src_stoi, src_itos = build_vocab(src_seqs)
tgt_stoi, tgt_itos = build_vocab(tgt_seqs)
f"Source (en) and target (az) vocab sizes: {len(src_stoi)}, {len(tgt_stoi)}"
'Source (en) and target (az) vocab sizes: 2109, 4362'
list(src_stoi.items())[:10]
[('<pad>', 0),
('<bos>', 1),
('<eos>', 2),
('<unk>', 3),
('go', 4),
('.', 5),
('run', 6),
('who', 7),
('?', 8),
('stay', 9)]
list(tgt_stoi.items())[:10]
[('<pad>', 0),
('<bos>', 1),
('<eos>', 2),
('<unk>', 3),
('get', 4),
('.', 5),
('qaç', 6),
('qaçın', 7),
('kim', 8),
('?', 9)]
# sanity check for encoding/decoding
s = src_seqs[0]
enc = encode(s, src_stoi)
dec = decode(enc, src_itos)
f"{s} -> {enc} -> {dec}"
"['go', '.', '<eos>'] -> [4, 5, 2] -> ['go', '.', '<eos>']"
It is useful to think of each minibatch as containing four main tensors: the padded source sequence, the shifted target sequence used as input, the valid source length, and the target labels. Symbolically, if the batch size is $B$ and the fixed sequence length is $T$, then a typical batch has shapes $$ \text{source} \in \mathbb{R}^{B \times T}, \qquad \text{target input} \in \mathbb{R}^{B \times T}, \qquad \text{labels} \in \mathbb{R}^{B \times T}. $$
The valid lengths form a vector in $\mathbb{R}^{B}$. This already shows an important difference from simple classification: here both the inputs and the targets are sequences. Later, once we introduce the encoder–decoder architecture, the “target input” will naturally become the input to the decoder.
MAX_LEN = 8 # num_steps
src = torch.tensor([pad(encode(s, src_stoi), MAX_LEN, src_stoi["<pad>"]) for s, _, _, _ in processed])
tgt = torch.tensor([pad(encode(t, tgt_stoi), MAX_LEN, tgt_stoi["<pad>"]) for _, t, _, _ in processed])
tgt_in = torch.tensor([pad(encode(d, tgt_stoi), MAX_LEN, tgt_stoi["<pad>"]) for _, _, d, _ in processed])
label = torch.tensor([pad(encode(l, tgt_stoi), MAX_LEN, tgt_stoi["<pad>"]) for _, _, _, l in processed])
src_valid_len = (src != src_stoi["<pad>"]).sum(1)
src.shape, tgt.shape, tgt_in.shape, label.shape, src_valid_len[:5]
(torch.Size([5000, 8]), torch.Size([5000, 8]), torch.Size([5000, 8]), torch.Size([5000, 8]), tensor([3, 3, 3, 3, 3]))
src[0], tgt[0], tgt_in[0], label[0], src_valid_len[0:3]
(tensor([4, 5, 2, 0, 0, 0, 0, 0]), tensor([4, 5, 2, 0, 0, 0, 0, 0]), tensor([1, 4, 5, 2, 0, 0, 0, 0]), tensor([4, 5, 2, 0, 0, 0, 0, 0]), tensor([3, 3, 3]))
The overall picture should be clear now. A machine translation dataset does not give us isolated tokens or fixed windows from one stream. Instead, each example is a pair of variable-length sequences from two different languages. To train neural sequence models efficiently, we preprocess the text, tokenize it, append special symbols such as <eos>, build separate vocabularies, and convert each sentence pair into fixed-length padded arrays. Once this structure is in place, we are ready to ask the central modeling question: how should a neural network read one sequence and generate another, especially when the two are unaligned and may differ in length?
Encoder-Decoder Architecture¶
Up to this point, we have constructed the dataset in a form suitable for neural networks. Each example consists of a source sequence, a decoder input sequence, and the corresponding labels. However, we have not yet defined how a model should transform the source sequence into the target sequence. As mentioned, main difficulty is that the two sequences are unaligned and may have different lengths. A fixed-window or feedforward approach is not sufficient here, because there is no direct positional correspondence between input and output tokens. Instead, we need a model that can read an entire sequence, form a representation of it, and then generate another sequence based on that representation. The standard solution is the encoder–decoder architecture, which we will see over and over again, including in our discussions about transformers and variational autoencoders. The idea is to split the model into two components:
- The encoder reads the source sequence $x_{1:T}$ and produces a representation (often called a state or context).
- The decoder generates the target sequence $y_{1:T'}$ one token at a time, conditioned on both this encoded representation and the previously generated tokens.

{kind=link}
Basically, instead of directly modeling $$ P(y_1, \dots, y_{T'} \mid x_1, \dots, x_T), $$ we introduce a latent representation $h$ computed by the encoder: $$ h = \text{Encoder}(x_1, \dots, x_T), $$ and then model the target sequence autoregressively: $$ P(y_1, \dots, y_{T'} \mid h) = \prod_{t=1}^{T'} P(y_t \mid y_1, \dots, y_{t-1}, h). $$
This separates the problem into two stages. We compress the source sequence into a representation, and then generate the target sequence conditioned on that representation. So the forward computation looks like:
$$
\text{enc\_state} = \text{Encoder}(\text{src}),
$$
$$
\text{logits} = \text{Decoder}(\text{dec\_in}, \text{enc\_state}),
$$
and we train by comparing logits with label using cross-entropy. This structure mirrors language modeling, but with an important extension: the decoder is no longer predicting purely from past tokens. It is also conditioned on the encoded source sequence. In other words, the decoder is a conditional language model. Before implementing Encoder and Decoder in the next section, we will implement simple batching with TensorDataset().
from torch.utils.data import TensorDataset, DataLoader
BATCH_SIZE = 256
dataset = TensorDataset(src, tgt, tgt_in, label)
loader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
src_batch, tgt_batch, tgt_in_batch, label_batch = next(iter(loader))
src_batch.shape, tgt_batch.shape, tgt_in_batch.shape, label_batch.shape
(torch.Size([256, 8]), torch.Size([256, 8]), torch.Size([256, 8]), torch.Size([256, 8]))
Sequence-to-Sequence Learning¶
We have already prepared the machine translation dataset in a form suitable for learning: each example consists of a source sequence, a decoder input sequence, and the corresponding labels. The next step is to specify a concrete model that can map one sequence to another. In sequence-to-sequence problems such as machine translation, both the input and the output are variable-length sequences, and the two are generally unaligned. This is exactly the kind of setting for which the encoder–decoder architecture was designed. In this section, we will implement that architecture using recurrent neural networks. More precisely, both the encoder and the decoder will be implemented as RNNs, so the entire model will be a recurrent sequence-to-sequence model. This is the classical seq2seq setup.

{kind=link}
The encoder RNN reads the source sequence token by token and transforms it into a hidden representation. In the simplest formulation, this representation is the final hidden state of the encoder, which acts as a compressed summary of the entire source sentence. The decoder RNN then uses this encoded representation to generate the target sequence one token at a time. Thus, instead of directly learning an arbitrary mapping from one variable-length sequence to another, we decompose the task into two parts: first encode the source, then decode a target conditioned on that encoding.
Note
This design is powerful, but it also introduces an important bottleneck. If the entire source sequence must be compressed into a single fixed-size hidden state, then the model may struggle when the input becomes long or information-dense. Later, attention mechanisms will address this limitation by allowing the decoder to access the encoder outputs more directly.
There is also a subtle but important distinction between training and prediction. During training, the decoder is usually given the correct previous target tokens as input. That is, when predicting the next target token, we feed the decoder the true target prefix rather than its own previous guesses. This is called teacher forcing. It stabilizes optimization because the decoder always conditions on the correct history. At inference time, however, the true target sequence is unknown, so the decoder must feed its own predictions back into itself step by step. Thus, training and generation follow the same autoregressive logic, but differ in what is used as the previous token.
class Encoder(nn.Module):
def __init__(self, vocab_size, hidden_size, embedding_dim, num_layers=1):
super().__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.gru = nn.GRU(embedding_dim, hidden_size, batch_first=True, num_layers=num_layers)
def forward(self, X, h=None):
emb = self.embedding(X)
if h is None:
h = emb.new_zeros(self.num_layers, emb.shape[0], self.hidden_size)
output, h = self.gru(emb, h)
return output, h
The encoder takes the source sequence X of shape $B \times T$ (batch size × sequence length) and converts it into a hidden representation. As usual, the embedding layer maps each token index to a dense vector. Note that we are using ready nn.GRU module provided by PyTorch which provides two outputs: output contains hidden states for every time step, while h is the final hidden state. We will use the final hidden state h as a summary of the entire source sequence and pass it to the decoder.
class Decoder(nn.Module):
def __init__(self, vocab_size, hidden_size, embedding_dim, num_layers=1):
super().__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.gru = nn.GRU(embedding_dim, hidden_size, batch_first=True, num_layers=num_layers)
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, X, h):
emb = self.embedding(X)
output, h = self.gru(emb, h)
logits = self.fc(output)
return logits, h
The key difference in the decoder is that it does not start from scratch. Instead of initializing its hidden state arbitrarily, it receives the final hidden state from the encoder. This allows the decoder to condition its generation on the source sequence. The decoder input X is the shifted target sequence (tgt_in), beginning with <bos>. During training, this corresponds to teacher forcing, where the decoder is given the true previous target tokens and learns to predict the next one at each time step. Finally, unlike the encoder, the decoder must produce predictions at every step. The GRU outputs are therefore passed through a linear layer to obtain logits, which are scores over the target vocabulary.

{kind=link}
class EncoderDecoder(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, hidden_size, embedding_dim, num_layers=1):
super().__init__()
self.src_vocab_size = src_vocab_size
self.tgt_vocab_size = tgt_vocab_size
self.enc = Encoder(src_vocab_size, hidden_size, embedding_dim, num_layers)
self.dec = Decoder(tgt_vocab_size, hidden_size, embedding_dim, num_layers)
self.loss_fn = nn.CrossEntropyLoss(ignore_index=tgt_stoi["<pad>"])
def calc_loss(self, logits, labels):
return self.loss_fn(logits.reshape(-1, self.tgt_vocab_size), labels.reshape(-1))
def forward(self, src, tgt_in):
_, h = self.enc(src)
logits, h = self.dec(tgt_in, h)
return logits, h
The EncoderDecoder class simply combines the two components into a single model and defines how data flows through them. In the forward pass, the source sequence src is first passed through the encoder, which returns the final hidden state. This hidden state is then used to initialize the decoder. The decoder receives tgt_in together with this state and produces logits over the target vocabulary at each time step. Thus, the class implements the full computation
$$
\text{src} \rightarrow \text{Encoder} \rightarrow h \rightarrow \text{Decoder}(tgt\_in, h) \rightarrow \text{logits}.
$$
The loss is computed by comparing these logits with label using cross-entropy, ignoring <pad> tokens. This completes the sequence-to-sequence training pipeline: encode the source, decode the target, and optimize the model to predict the correct next token at every position.
SRC_VOCAB_SIZE = len(src_stoi)
TGT_VOCAB_SIZE = len(tgt_stoi)
HIDDEN_SIZE = 256
EMBED_DIM = 128
NUM_LAYERS = 2
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
enc_dec = EncoderDecoder(
SRC_VOCAB_SIZE, TGT_VOCAB_SIZE, HIDDEN_SIZE, EMBED_DIM, NUM_LAYERS
).to(device)
optimizer = torch.optim.AdamW(enc_dec.parameters(), lr=3e-4)
# sanity check
src_batch, _, tgt_in_batch, lbl_batch = next(iter(loader))
src_batch = src_batch.to(device)
tgt_in_batch = tgt_in_batch.to(device)
lbl_batch = lbl_batch.to(device)
logits, h = enc_dec.forward(src_batch, tgt_in_batch)
loss = enc_dec.calc_loss(logits, lbl_batch)
logits.shape, h.shape, loss.item()
(torch.Size([256, 8, 4362]), torch.Size([2, 256, 256]), 8.360295295715332)
Before training on the full dataset, it is useful to verify that the model behaves correctly on a small input and check tensor shapes / values. A stronger check is to deliberately overfit on a single batch. Here, we repeatedly train the model on the same batch and observe whether the loss decreases. Since the model sees exactly the same data every time, it should be able to memorize it. If the loss does not go down, this usually indicates a bug in the model, data pipeline, or optimization setup. Once this check passes, we can confidently proceed to training on the full dataset.
# overfitting to a single batch
epochs = 100
for epoch in range(epochs):
logits, h = enc_dec(src_batch, tgt_in_batch)
loss = enc_dec.calc_loss(logits, lbl_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f"{epoch+1}/{epochs} | loss: {loss.item():.4f}")
10/100 | loss: 7.5890 20/100 | loss: 5.4970 30/100 | loss: 4.6702 40/100 | loss: 4.3117 50/100 | loss: 4.1025 60/100 | loss: 3.9580 70/100 | loss: 3.8401 80/100 | loss: 3.7405 90/100 | loss: 3.6520 100/100 | loss: 3.5689
After verifying that the model can overfit a single batch, we proceed to training on the full dataset. We should not expect perfect results in this setting. There are several limitations. First, the dataset is relatively small, so the model does not see enough variations of language to generalize well. Second, the model itself is simple: a basic GRU encoder–decoder without attention. This means the entire source sentence must be compressed into a single fixed-size hidden state, which can limit performance, especially for longer or more complex sentences. Third, training is relatively short and the model capacity is modest, so it cannot capture all linguistic structure.
As a result, the model will often produce imperfect translations. Some outputs may be partially correct, while others may be grammatically incorrect or semantically off. The goal here is to demonstrate that the seq2seq model learns a meaningful mapping between source and target sequences. The model should start producing outputs that resemble the target language, capture common words and structures (e.g. length). This indicates that the encoder–decoder framework and training pipeline are working as intended. More advanced models, larger datasets, and techniques such as attention and beam search will significantly improve performance in later sections.
Finally, we use simple word-level tokenization, where each sequence is split into words and punctuation marks. This choice keeps the pipeline simple and easy to follow, but it comes with trade-offs. Word-level tokenization leads to relatively large vocabularies, and any word not seen during training must be mapped to the special <unk> token. As a result, the model cannot handle rare or unseen words well. In contrast, modern systems often use subword tokenization methods (such as BPE or WordPiece), which break words into smaller units and significantly improve coverage.
epochs = 500
enc_dec.train()
for epoch in range(epochs):
total_loss = 0.0
for src_batch, _, tgt_in_batch, lbl_batch in loader:
src_batch = src_batch.to(device)
tgt_in_batch = tgt_in_batch.to(device)
lbl_batch = lbl_batch.to(device)
logits, _ = enc_dec(src_batch, tgt_in_batch)
loss = enc_dec.calc_loss(logits, lbl_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if (epoch + 1) % (epochs // 10) == 0:
print(f"{epoch+1}/{epochs} | loss: {total_loss / len(loader):.4f}")
50/500 | loss: 1.5439 100/500 | loss: 0.4825 150/500 | loss: 0.2155 200/500 | loss: 0.1475 250/500 | loss: 0.1267 300/500 | loss: 0.1197 350/500 | loss: 0.1134 400/500 | loss: 0.1107 450/500 | loss: 0.1087 500/500 | loss: 0.1077
Similar to our sample_names() function in character-level models, it is logical to create translate() function which will take a sentence as its input and translate. Alas, we won't achieve desirable results.
def translate(model, sentence, max_len=MAX_LEN):
model.eval()
device = next(model.parameters()).device
src_tokens = preprocess(sentence).split() + ["<eos>"]
src_ids = pad(encode(src_tokens, src_stoi), MAX_LEN, src_stoi["<pad>"])
src_tensor = torch.tensor([src_ids], device=device)
with torch.no_grad():
_, h = model.enc(src_tensor)
dec_input = torch.tensor([[tgt_stoi["<bos>"]]], device=device)
generated = []
for _ in range(max_len):
logits, h = model.dec(dec_input, h)
next_id = logits[:, -1, :].argmax(dim=-1, keepdim=True)
token = tgt_itos[next_id.item()]
if token == "<eos>":
break
if token not in {"<pad>", "<bos>"}:
generated.append(token)
dec_input = next_id
return " ".join(generated)
translate(enc_dec, "We are happy .")
'biz əkizik .'
translate(enc_dec, "Will they go to school ?")
'onlar hara getmək istəyirlər ?'
translate(enc_dec, "This is a nice book .")
'bu mənim kompüterimdir .'
translate(enc_dec, "Badambura is great.")
'ürəyim çırpınır .'
translate(enc_dec, "She knows a lot !")
'o , tam haqqlıdır ?'
BLEU¶
So far, we have evaluated the model qualitatively by inspecting generated translations. While this is useful, it is subjective and does not scale. We need a way to compare predicted sequences with ground-truth translations more systematically. A common approach is the BLEU (Bilingual Evaluation Understudy) score. Instead of checking whether the entire sentence matches exactly, BLEU measures how many short subsequences (n-grams) in the predicted sentence also appear in the reference sentence. For example, unigrams check individual words, bigrams check pairs of consecutive words, and so on. This allows us to reward partial correctness rather than requiring exact matches.
BLEU computes a weighted product of n-gram precisions, while also applying a penalty if the predicted sentence is too short. This is important because very short predictions can achieve artificially high precision by matching only a few tokens. A perfect match between prediction and reference yields a BLEU score of 1, while completely unrelated sentences yield a score close to 0. Formally, it is defined as $$ \text{BLEU} = \text{BP} \cdot \exp\left( \sum_{n=1}^{N} w_n \log p_n \right), $$ where $p_n$ is the precision of n-grams of length $n$, and $w_n$ are weights (typically uniform, e.g. $w_n = \frac{1}{N}$). The brevity penalty $\text{BP}$ is given by $$ \text{BP} = \begin{cases} 1, & \text{if } \ell_{\text{pred}} > \ell_{\text{ref}} \\ \exp\left(1 - \frac{\ell_{\text{ref}}}{\ell_{\text{pred}}}\right), & \text{otherwise} \end{cases} $$ where $\ell_{\text{pred}}$ and $\ell_{\text{ref}}$ are the lengths of the predicted and reference sequences. This formulation encourages both local accuracy (via n-gram matches) and reasonable sequence length.
BLEU provides a simple way to quantify how close the generated translations are to the ground truth. It is not perfect: it does not capture meaning directly and may penalize valid alternative translations. However, it is widely used and gives a reasonable signal of model performance, especially for small experiments like ours.
Exercise
Implement and test the BLEU metric.
Beam Search¶
So far, our decoder has generated translations using a simple greedy strategy: at each time step, it selects the token with the highest probability and immediately feeds that token back into the decoder. This is fast and easy to implement, but it can be suboptimal. A sequence that looks best at one step may lead to a poor overall translation later. In other words, greedy decoding makes a locally best choice at each step, but local decisions do not always produce the globally best sequence. A clearer way to see this is with a small table of candidates. At the first step:
| token | $P(\cdot \mid x)$ |
|---|---|
| $a$ | 0.40 |
| $b$ | 0.35 |
| $c$ | 0.25 |
Greedy decoding picks $a$. Now consider the best continuations:
| sequence | step probabilities | total probability |
|---|---|---|
| $a \;\texttt{<eos>}$ | $0.40 \times 0.20$ | 0.08 |
| $b \; d \;\texttt{<eos>}$ | $0.35 \times 0.90 \times 0.90$ | 0.2835 |
Even though $a$ was the best local choice at the first step, the sequence starting with $b$ is much better overall: $0.2835 > 0.08$. Greedy decoding cannot recover from this early decision, because it never considers $b$ once $a$ is chosen.
Beam search is a simple improvement over greedy decoding. Instead of keeping only one partial hypothesis at each step, we keep the top $k$ candidates, where $k$ is the beam width. At every decoding step, each current candidate is expanded by possible next tokens, and from all resulting continuations we keep only the best $k$ according to their accumulated scores. This allows the decoder to explore multiple plausible translations in parallel rather than committing too early to a single path.

{kind=link}
If the beam width is $1$, beam search reduces exactly to greedy decoding. As the beam width increases, decoding becomes more expensive, but it also has a better chance of finding a stronger overall sequence. In practice, small beam widths such as $2$, $3$, or $5$ are often enough to improve results substantially.
Exercise
Replace greedy decoding with beam search and use it to generate candidate translations more carefully.
Conclusion¶
We began with the simplest autoregressive models, where each token is predicted from a limited context, and gradually expanded this idea from n-gram assumptions to recurrent models that maintain a learned hidden state. This allowed us to move from modeling a single sequence to modeling conditional relationships between sequences. Machine translation made this shift explicit: instead of predicting the next token in isolation, we now generate an entire sequence conditioned on another.
The encoder–decoder architecture provided the necessary structure for this transition. The encoder compresses the source sequence into a representation, and the decoder generates the target sequence autoregressively from this representation. With a recurrent implementation, this gives a complete sequence-to-sequence pipeline, including training with teacher forcing, autoregressive generation, and evaluation with BLEU. We also saw that decoding itself is nontrivial, since greedy choices can be suboptimal, motivating more careful strategies such as beam search.
At the same time, the limitations of this approach are clear. Compressing the entire source sequence into a single hidden state is restrictive, especially for longer or more complex inputs. Many of the errors we observe stem from this bottleneck rather than from the training procedure itself. This naturally leads to the need for more powerful models that can access the full sequence more directly. In the next lecture, we address this by introducing attention mechanisms and, ultimately, transformer architectures, which remove this bottleneck and significantly improve sequence modeling.