The following material was initially prepared as a lecture for ENCE 3503: Data & Information Engineering (Fall 2024) course at ADA University.
![]()
Data we wish to work with are rarely available (e.g. as a .csv file) suiting our needs. Often we need to be proactive and obtain data ourselves. We have vast amount of web resources for that, however, manually retrieving data is a slow and not scalable process. Therefore, the automation of this task called web scraping will be handy in many situations.
You may even stumble upon a job announcement (as of November 2024) while “sniffing around” robots.txt file of big companies such as tripadvisor.com. (What is robots.txt will be discussed soon.)
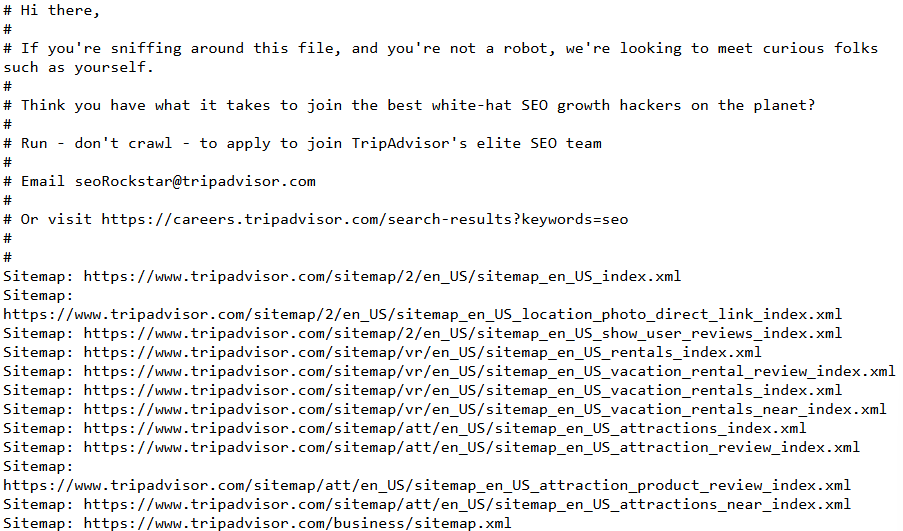
Table of Contents
Ethical Considerations
- Respect for Privacy. Not collecting sensitive information without consent.
- Website Performance. Web scraping can overload website’s servers, affecting its performance.
- Transparency and Accountability. Being open with web scraping methods and purposes can mitigate concerns from website owners/users.
Legal Considerations
- Terms of Service Violation. Some websites have ToS which prohibit web scraping, making it illegal by law.
- Copyright Infringement. Scraping copyrighted data may also lead to legal repercussions.
- Privacy Laws. Scraping personal and sensitive data can violate privacy regulations of different governments.
- Unauthorized Access. Scraping data from not publicly available websites is basically digital trespassing and can lead to legal consequences.
Case Studies
Web Scraping Best Practices
- Read and understand Terms of Services.
- Use official APIs if available.
- Follow
robots.txtfile if available in order to not access restricted pages. - Get consent for using personal/sensitive data.
- Scrape only necessary data and not burden the website.
A quick article, Ethics in Web Scraping by James Densmore is worth reading.
Public API & Access Token
Many social media websites usually provide their own API for scraping data (and not only). For example, you can “programmatically query data, post new stories, manage ads, upload photos, and perform a wide variety of other tasks” with Facebook’s Graph API.
Kaggle also provides its own public API. For authentication, you need to get access token from the account settings which will generate a kaggle.json file. After you download the file, you can use its content as a dictionary to set environment variables for Python to use.
# kaggle.json
token = {
"username":"YOUR_KAGGLE_USERNAME",
"key":"YOUR_KAGGLE_KEY"
}
import os
os.environ["KAGGLE_USERNAME"] = token["username"]
os.environ["KAGGLE_KEY"] = token["key"]
The token is set and we can connect to Kaggle API now. We will install kaggle library and call some API commands.
pip install kaggle
kaggle competitions list
We can download the datasets with:
kaggle datasets download -d DATASET_PATH
where DATASET_PATH is a part of the URL coming after kaggle.com/datasets. Full documentation can also be found in Kaggle’s Github Repository.
User Agent & Robots.txt
User Agent is a string that a client (e.g. web browser) sends to a web server to identify itself. It can contain information about browser, operating system, device type. User agents help servers recognize the type of client and adjust responses if needed (e.g. serve different content to a mobile browser). You can think of user agents as being the opposite of access token (access token is provided to us by the API, whilst it is us who provides the user agent string to the server in order to keep transparency). It may look like this:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Or if it is Google bot crawler, like this:
Googlebot/2.1 (+http://www.google.com/bot.html)
Robots.txt is a file placed in the root directory of a website (e.g. example.com/robots.txt) which has instructions to web crawlers about which web pages they can access. Try to understand what robots.txt file instructs below:
User-agent: Googlebot
Disallow: /private/
User-agent: *
Disallow: /temp/
How to see robots.txt file content of any website?
import os
import requests
url = "https://shahaliyev.org"
response = requests.get(os.path.join(url, "robots.txt"))
print(response.text)
Web Scraping in Python
The main Python libraries to be aware of for web scraping are BeautifulSoup and requests / urllib (urllib2).
The implementation below is not using requests (my bad) which is a better choice than urllib.
from bs4 import BeautifulSoup
from urllib.parse import urlparse, urljoin
from urllib.robotparser import RobotFileParser
from urllib.request import Request, urlopen
We can write a Python function which will check if we can scrape the web page or not based on our user agent string.
def can_scrape(url, user_agent='*'):
"""
Checks whether a specific URL can be scraped according to the
rules defined in the site's robots.txt file.
Parameters:
url (str): URL path to check with scheme (e.g., 'http', 'https')
user_agent (str): The user agent string for robots.txt.
Defaults to * which is generic user agent.
Returns:
bool: True if the specified user agent is allowed to scrape the URL.
Example:
can_scrape("https://www.example.com/path/to/resource", "MyScraper/1.0")
"""
parsed_url = urlparse(url)
base_url = f"{parsed_url.scheme}://{parsed_url.netloc}"
robots_url = urljoin(base_url, "/robots.txt")
rp = RobotFileParser()
rp.set_url(robots_url)
rp.read()
return rp.can_fetch(user_agent, url)
Understanding Web Page Structure
Once we read ToS and consider robots.txt, we can start scraping allowed web pages. The knowledge of basic web page content (generally html) structure is essential for that. On a browser you can right click and inspect the web page.

From inspection, we can see that each post title, link, as well as date are inside writing class. We can get the list of all html elements of the same class with the help of find_all() function of BeautifulSoup.
url = "https://shahaliyev.org/"
with urlopen(url) as response:
html = response.read()
soup = BeautifulSoup(html, 'html.parser')
post_list = soup.find_all(class_='writing')
post_list[0]
The function below is overkill for our purposes and will work only for two urls, https://shahaliyev.org/ and https://shahaliyev.org/az/. However, it is possible to easily modify the function to suit your purposes and scrape many similiarly structured urls of a large website (e.g. category pages of a news website).
import pandas as pd
def scrape_writings(url, user_agent="*", count=5):
"""
Args:
url (str): The URL of the writings page to scrape.
user_agent (str): The user agent string to be used for making requests.
Default is "*" (generic user agent).
count (int): The number of writings to scrape from the page. Default is 5.
Returns:
pandas.DataFrame: A DataFrame containing the titles, dates, and links.
Notes:
The function assumes that the:
- links are stored in `<a>` tag.
- writings are stored in `<div class="writing">`
- titles are stored within `<a class="post-link">`
- dates are stored in `<time class="post-date">` elements.
Raises:
Exception: Any network or parsing errors will raise an exception if encountered.
None will be returned.
"""
if not can_scrape(url, user_agent=user_agent):
print(f"Scraping not allowed for {url}")
return
try:
request = Request(url, headers={"User-Agent": user_agent})
with urlopen(request) as response:
html = response.read()
soup = BeautifulSoup(html, 'html.parser')
parsed_url = urlparse(url)
base_url = f"{parsed_url.scheme}://{parsed_url.netloc}"
data = {
"title": [],
"date": [],
"link": [],
}
writings = soup.find_all(class_='writing')
for writing in writings[:count]:
title = writing.find('a', class_='post-link')
date = writing.find('time', class_='post-date')
link = title if title else writing.find('a', href=True)
title = title.text.strip() if title else pd.NA
date = date['datetime'].strip() if date else pd.NA
link = urljoin(base_url, link['href']) if link else pd.NA
data["title"].append(title)
data["date"].append(date)
data["link"].append(link)
return pd.DataFrame(data)
except Exception as e:
print(f"Error scraping the URL {url}: {e}")
return None
As the reference link is relative, we need to extract the base url. In our case, scheme of URL will be https, and network location part of URL will be shahaliyev.org. The rest of the links will be appended to this base url.
Comments
Powered by Giscus · GitHub cookies may apply if you sign in